Veeam
Intro
Veeam Backup & Replication è un software di protezione dei dati progettato per ambienti virtualizzati, come VMware vSphere e Microsoft Hyper-V.
Veeam Backup & Replication aiuta le aziende a ripristinare rapidamente i dati critici in caso di guasti imprevisti del sistema, disastri o errori umani, senza interrompere le operazioni in corso. Il software offre funzionalità come il backup e la replica automatizzati, il ripristino granulare, il supporto per il backup nel cloud e il disaster recovery. Viene utilizzato da professionisti IT e amministratori di sistema di aziende di tutte le dimensioni per garantire la disponibilità e la resilienza dei dati.
Veeam Backup & Replication è un software molto complesso e ricopre molti scenari di utilizzo. Di seguito sarà possibile trovare le varie guide disponibili sui diversi casi d'uso.
Le versioni 10 e precedenti di Veeam Backup & Replication non sono più ufficialmente supportate da Veeam. Per maggiori informazioni sul ciclo di vita dei prodotti Veeam puoi consultare la seguente pagina.
VMware Direct Backup
Tra le varie nuove funzionalità di Veeam 12 è presente la possibilità di effettuare backup di macchine virtuali direttamente, senza creare uno scale-out repository, bypassando il requisito di un disco fisico sulla rete in cui appoggiare il backup (questo invece era obbligatorio con Veeam 11 per i backup di VM). Consente alle aziende di eseguire il backup, la replica e il ripristino di macchine virtuali (VM), applicazioni e dati con facilità, garantendo la continuità aziendale e riducendo i tempi di inattività.
Tuttavia, si dovrebbe tenere in considerazione che utilizzando il backup diretto su object storage senza lo scale-out, si potrebbero perdere alcune delle funzionalità avanzate di Veeam, come ad esempio la gestione centralizzata di più repository o la possibilità di distribuire i backup su più dispositivi di archiviazione per migliorare le prestazioni. Inoltre, il backup diretto su object storage senza lo scale-out potrebbe non essere adatto a scenari in cui è necessario un ripristino rapido dei dati, a causa delle limitazioni di velocità dell'object storage.
Prerequisiti
Per prima cosa, è necessario ottenere access key e secret key dalla Cubbit Web Console oppure https://console.[il-tuo-tenant].cubbit.eu. Si possono seguire queste istruzioni su come iniziare con un account Cubbit e generare queste chiavi.
Per procedere nella configurazione è necessario disporre di:
- Software Veeam Backup and Replication (Versione 12 e successive)
- Licenza Veeam Universal License (VUL) o Per-socket (Enterprise Plus o superiore)
- Ambiente di virtualizzazione (es. VMware) in caso di backup di macchine virtuali.
Le Community e Standard editions di Veeam Backup and Replication non permettono di utilizzare la funzionalità di Scale-out repository. Con l'edizione Enterprise, gli utenti possono creare due repository di Scale-out con tre estensioni attive e un numero illimitato di inattivi illimitati (posti in modalità di manutenzione). Le edizioni VUL e Enterprise Plus non hanno limitazioni sul numero di numero di repository o di estensioni.
Creare un Backup Repository Object Storage S3-Compatible
Dalla vista Backup Infrastructure, click destro su Backup Repositories e scegliere Add Backup Repository.
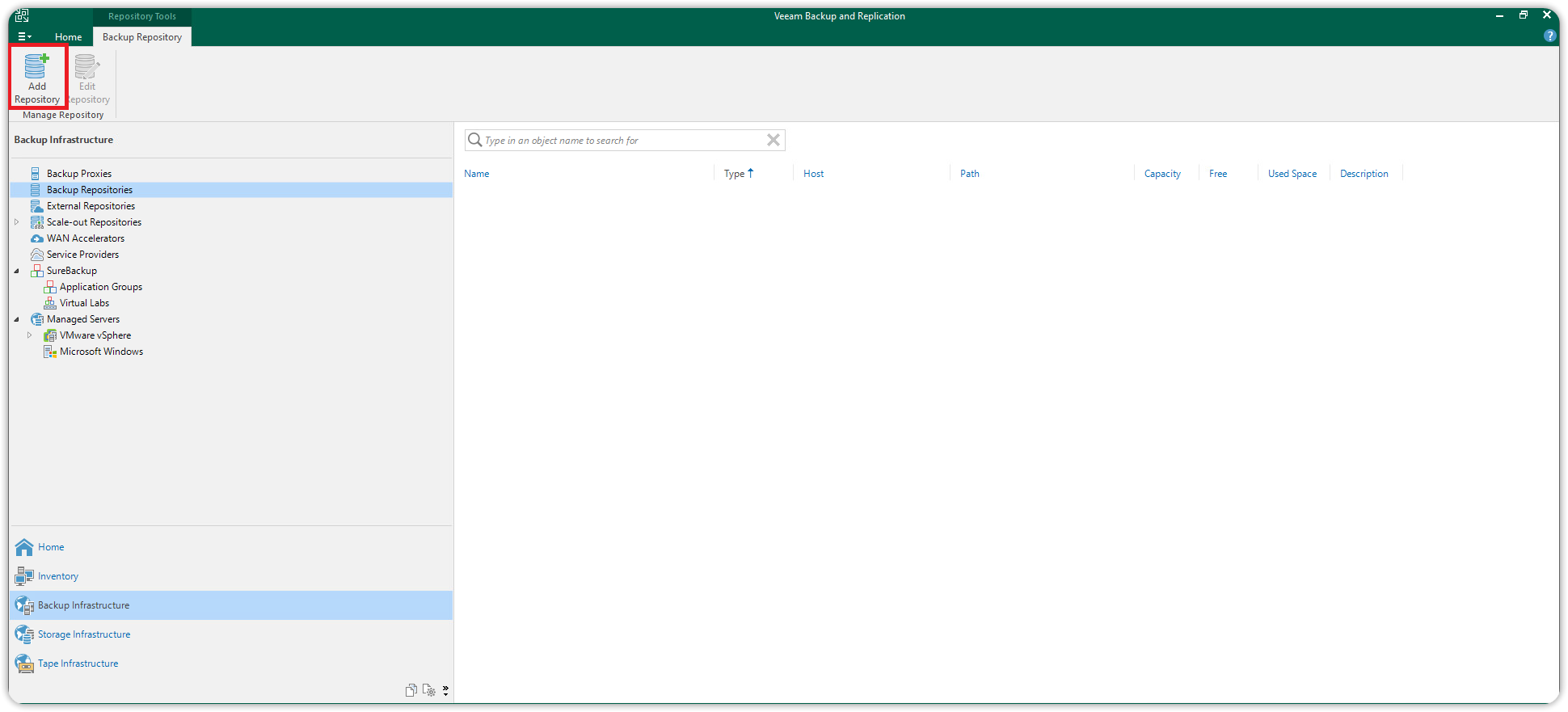
Dalla finestra Add Backup Repository, scegliere Object Storage.
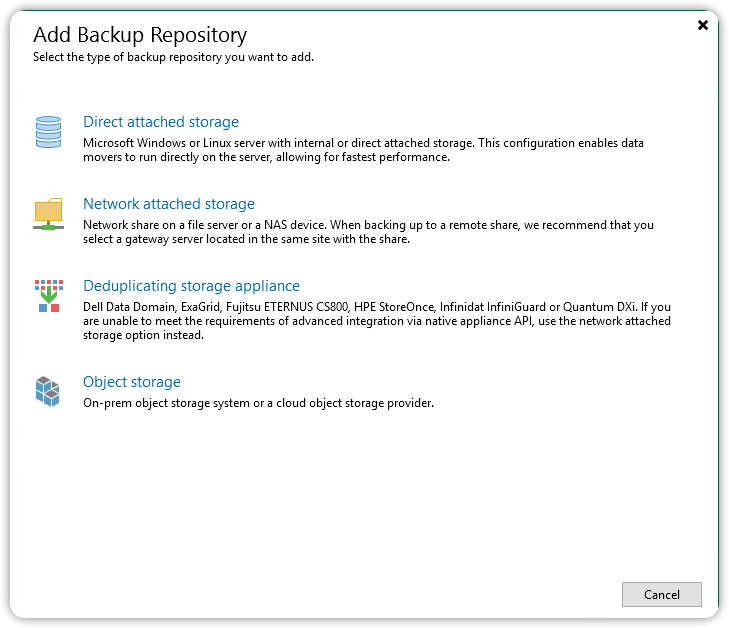
Scegliere S3 compatible object storage per avviare il wizard Object Storage Repository.

Inserire il nome e la descrizione per il nuovo repository Object Storage e cliccare Next.
Nella finestra Account inserire https://s3.cubbit.eu oppure s3.[il-tuo-tenant].cubbit.eu se hai un tenant personalizzato, nel campo Service point e inserire il valore eu-west-1 nel campo region. Nel campo delle credenziali fare click sul bottone Add per aggiungere le access credentials. Sul campo credentials premere il pulsante Add per aggiungere le credenziali di accesso; nella finestra di dialogo che si aprirà inserire Access key e Secret key nei rispettivi campi e cliccare OK.
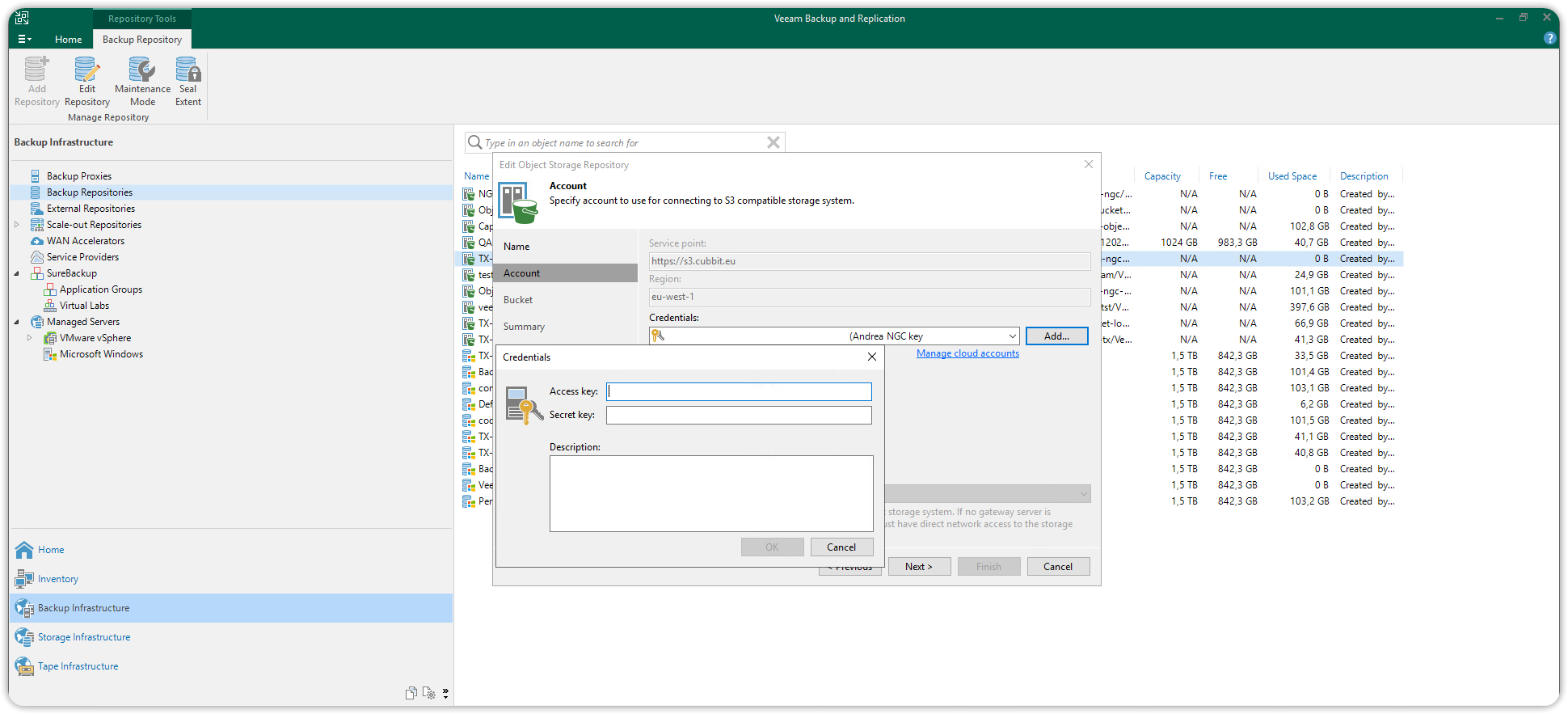
Prima di procedere ulteriormente sarà necessario aver creato almeno un Bucket tramite altri client S3 (ad esempio Amazon AWS CLI o Cubbit Web Console).
Attenzione: nel caso di backup su Object Storage via Veeam, deve essere evitato nel modo più assoluto l'utilizzo di S3 Versioning senza attivazione di S3 Object Lock (immutabilità). Senza l'immutabilità, infatti, vengono moltiplicate sia le operazioni necessarie alla cancellazione, sia lo spazio totale utilizzato, a totale svantaggio del cliente.
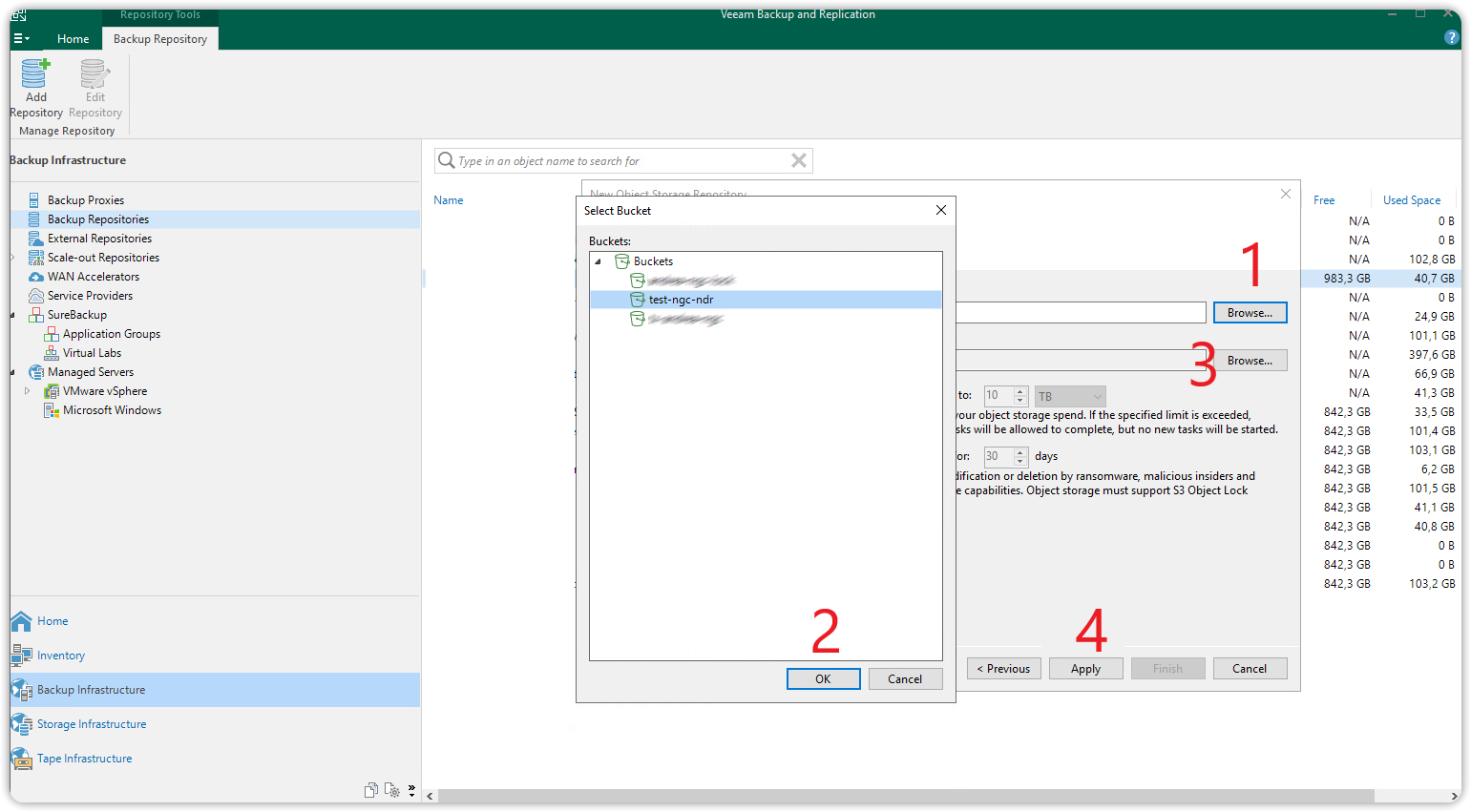
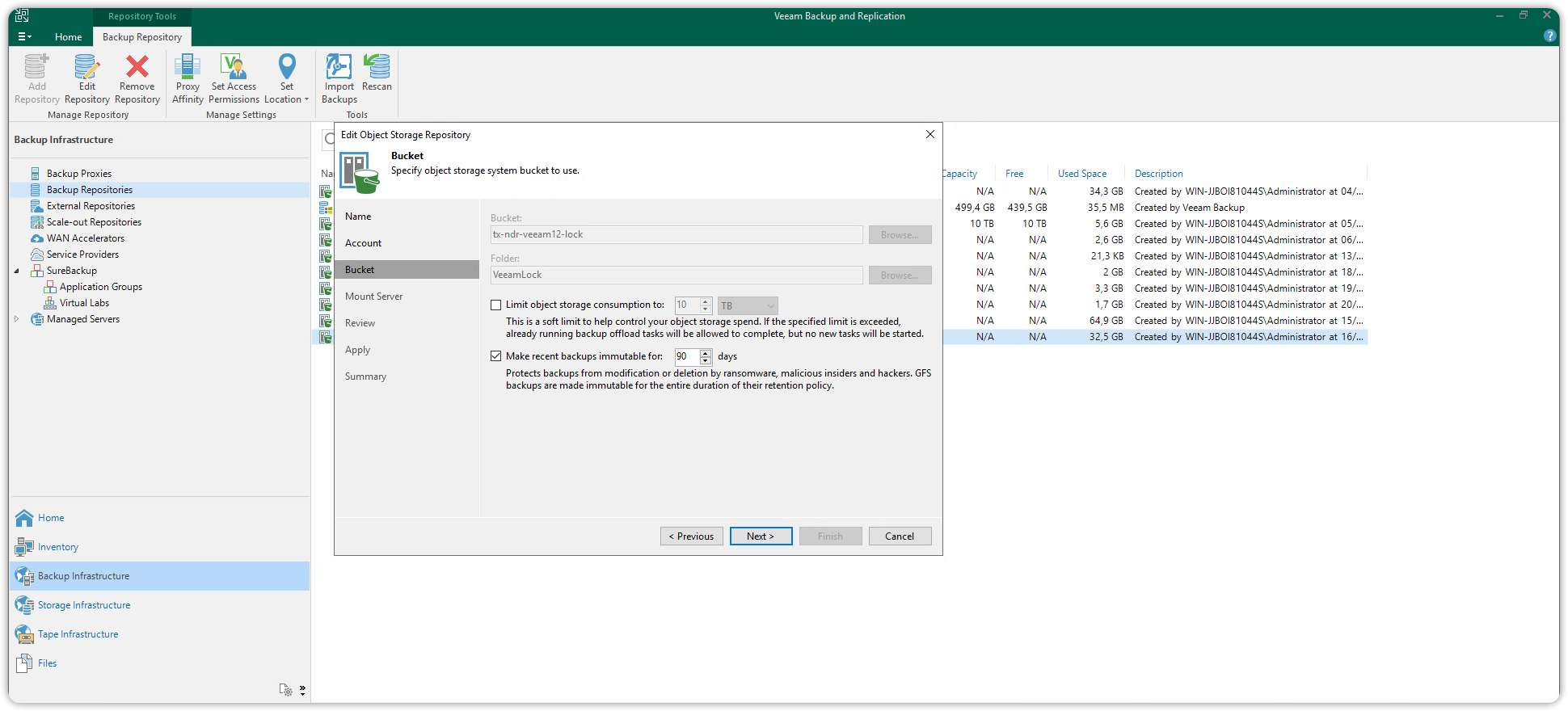
Dopo avere creato un nuovo bucket dalla Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu procedere adesso con la sezione Bucket.
Questa finestra permette, tramite il pulsante Browse più in alto (1), di navigare tra i bucket presenti sul vostro account S3 Cubbit. Dopo avere selezionato il bucket premere OK (2) e chiudere la finestra di dialogo.
Allo stesso modo, cliccando il pulsante Browse (3) più in basso, sarà possibile navigare tra le cartelle all'interno del bucket scelto o crearne una nuova (pulsante New folder).
Il bucket e la cartella scelti saranno la destinazione dei backup. Per andare avanti selezionare la cartella e premere OK. Successivamente cliccare il pulsante Apply (4).
Rivedere le informazioni e finalmente cliccare Finish per completare questo passaggio. Il repository Cubbit Object Storage S3-Compatible è stato aggiunto con successo su Veeam 12, sarà disponibile come target-repository sul Backup Job che verrà creato d'ora in avanti.
Creazione del Backup job
Con Veeam 12 adesso sarà possibile creare un backup job e inserire direttamente come backup repository il repository S3 Object Storage che è stato creato allo step precedente anche per le macchine virtuali.
Per procedere è sufficiente creare un nuovo backup job scegliendo la macchina virtuale di cui si vuole effettuare il backup. Come Backup repository si dovrà selezionare il repository S3 creato precedentemente. Premere poi il pulsante Advanced in basso a destra per entrare nella configurazione avanzata.
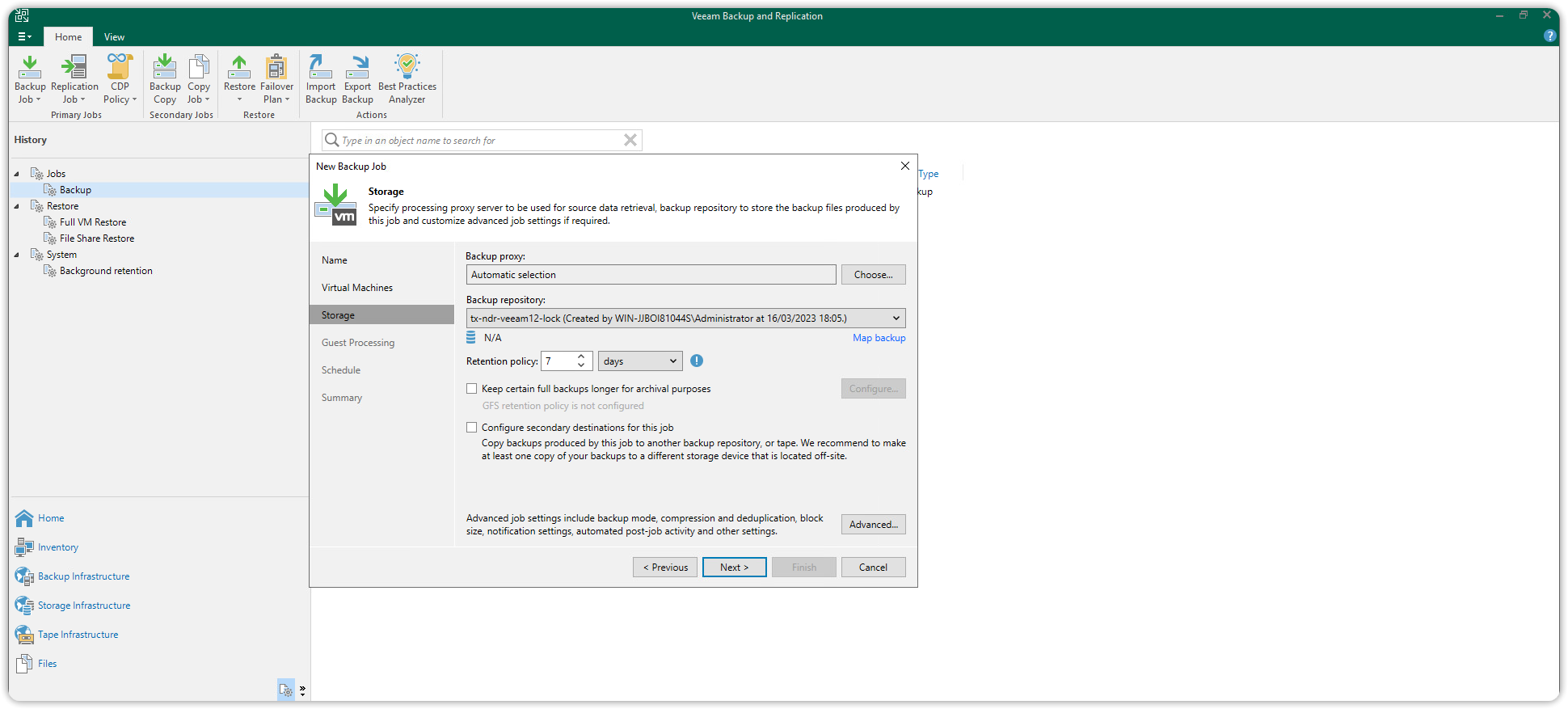
Selezionare la scheda Storage in alto e sotto Storage optimization: impostare 4 MB e premere OK.
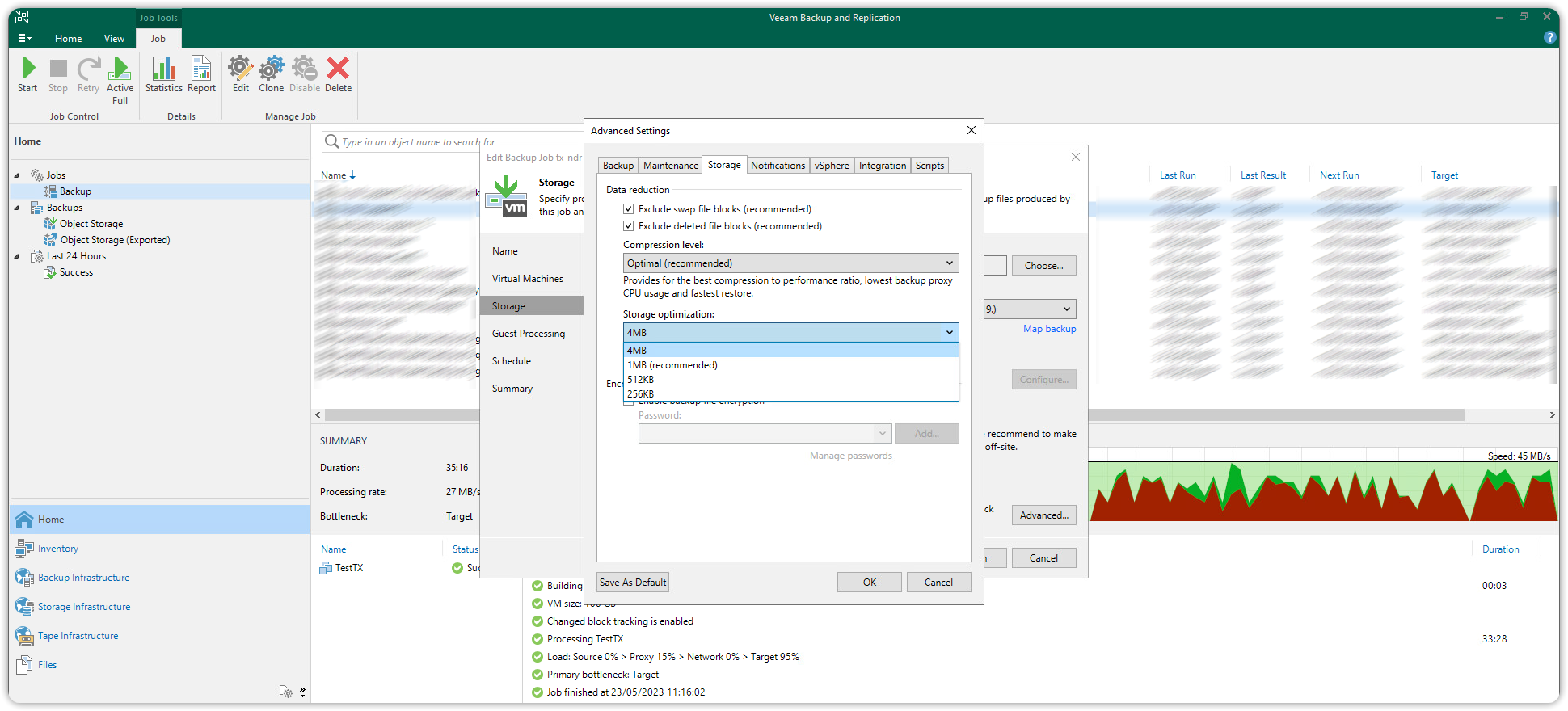
Procedere con il completamento della creazione del backup job e lanciarlo o schedulare il suo avvio.
Per maggiori informazioni sull'utilizzo di Veeam Backup & Replication potete consultare la documentazione ufficiale.
Immutabilità
L'immutabilità è una caratteristica delle soluzioni di backup e ripristino dati di Veeam che consente di proteggere i dati da modifiche indesiderate e da eventuali attacchi informatici come ad esempio i ransomware. L'immutabilità di Veeam si basa sulla creazione di un backup dati o di un'immagine del disco i cui dati non possono essere modificati una volta creati. Ciò significa che i dati vengono scritti in un repository di backup o in un archivio che non consente la modifica, la cancellazione o l'aggiunta di dati.
Questo tipo di immutabilità può essere implementato utilizzando il sistema di archiviazione object-based di Veeam, che consente di impostare una regola di retention dei dati in modo che non possano essere eliminati o modificati per un determinato periodo di tempo. In questo particolare caso è possibile utilizzare la funzione S3 Object Lock supportata da Cubbit S3 Object Storage.
Requisiti Immutabilità
Per prima cosa, è necessario ottenere access key e secret key dalla Cubbit Web Console oppure https://console.[il-tuo-tenant].cubbit.eu. Si possono seguire queste istruzioni su come iniziare con un account Cubbit e generare queste chiavi.
Per procedere nella configurazione di un repository S3 e attivare la funzione di Immutabilità è necessario disporre di:
- Software Veeam Backup and Replication (Versione 9 o successive)
- La licenza Veeam minima richiesta dipende dal tipo di backup e caso d'uso specifico che si intende intraprendere. Confronto tra le licenze Veeam.
Creare un Backup Repository Object Storage S3 da un bucket con S3 Object Lock attivo
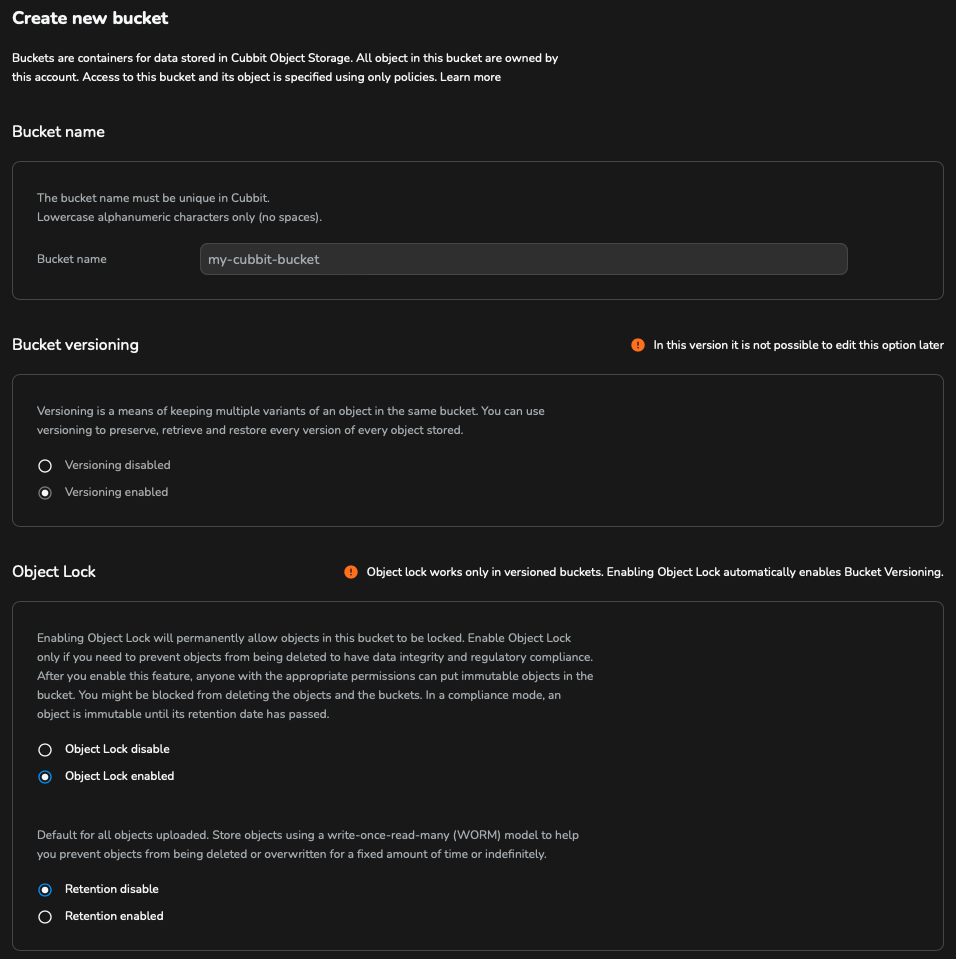
Per prima cosa è necessario creare un bucket dalla Cubbit Web Console oppure https://console.[il-tuo-tenant].cubbit.eu. E' possibile seguire le istruzioni su S3 Object Lock per attivare l' S3 Object Lock alla creazione del bucket.
Dopo avere attivato sia S3 Versioning che S3 Object Lock sul bucket selezionato è necessario impostare la retention su disabled come da immagine seguente. Sarà poi Veeam a gestire la retention policy e a configurarla. Attenzione che, nel caso di backup su Object Storage con Veeam, l'utilizzo di S3 Versioning senza attivazione di S3 Object Lock (immutabilità) deve essere assolutamente evitato. Senza l'immutabilità, infatti, vengono moltiplicate sia le operazioni necessarie alla cancellazione sia lo spazio totale utilizzato, a totale svantaggio del cliente.
Dalla vista Backup Infrastructure, click destro su Backup Repositories e scegliere Add Backup Repository.
Dalla finestra Add Backup Repository scegliere Object Storage.
Scegliere S3 compatible object storage per avviare la procedura guidata Object Storage Repository.
Inserire il nome e la descrizione per il nuovo repository Object Storage e cliccare Next.
Nella finestra Account inserire https://s3.cubbit.eu/ oppure s3.[il-tuo-tenant].cubbit.eu se hai un tenant personalizzato, nel campo Service point e inserire il valore eu-west-1 nel campo region. Sul campo credentials premere il pulsante Add per inserire le credenziali di accesso. Sul campo credentials premere il pulsante Add per aggiungere le credenziali di accesso; nella finestra di dialogo che si aprirà inserire Access key , Secret key nei rispettivi campi e premere OK.
Questa finestra permette, tramite il pulsante Browse più in alto, di navigare tra i bucket presenti sul vostro account S3 Cubbit. Dopo avere selezionato il bucket con l'object lock abilitato, premere OK e chiudere la finestra di dialogo.
Allo stesso modo, cliccando il pulsante Browse più in basso, sarà possibile navigare tra le cartelle all'interno del bucket scelto o crearne una nuova (pulsante New folder).
Il bucket e la cartella scelti saranno la destinazione dei backup. Per andare avanti selezionare la cartella e premere OK. Spuntare la casella "Make recent backups immutable for" e indicare per quanti giorni rendere immutabili i backup su questo bucket.
Veeam Backup & Replication aggiunge automaticamente 10 giorni al valore impostato su questa casella denominato periodo di block generation per il backup job iniziale. Per maggiori informazioni puoi consultare la documentazione ufficiale sull'immutabilità.
Successivamente premere Next.
Rivedere le informazioni, quindi cliccare Finish per completare questo step. L'Immutabilità è adesso impostata. Il repository Cubbit Object Storage S3 Compatible con S3 Object Lock abilitato è stato aggiunto con successo su Veeam, sarà disponibile come target-repository sul Backup Job che verrà creato d'ora in poi.
Per maggiori informazioni sull'utilizzo di Veeam Backup & Replication potete consultare la documentazione ufficiale
Backup NFS
In questo caso d'uso supporremo di dover procedere al backup su Cubbit tramite una share NFS di rete.
Requisiti per Backup NFS
Per prima cosa, è necessario ottenere access key e secret key dalla Cubbit Web Console oppure https://console.[il-tuo-tenant].cubbit.eu. Si possono seguire queste istruzioni su come iniziare con un account Cubbit e generare queste chiavi.
Per procedere nella configurazione è necessario disporre di:
- Software Veeam Backup and Replication (Versione 11 e successive)
- Licenza Veeam Universal License (VUL) o Per-socket (Enterprise o superiore)
- Un File Share che soddisfi i requisiti elencati in Supporto delle piattaforme
- Se si prevede di utilizzare un server proxy di backup dedicato o un cache repository, assicurarsi che questi componenti siano aggiunti in Backup Infrastructure.
Backup Repository (Capacity tier)
Dalla vista Backup Infrastructure, fare click destro su Backup Repositories e scegliere Add Backup Repository.
Dalla finestra Add Backup Repository, scegliere Object Storage.
Scegliere S3-Compatible Object Storage per avviare la procedura guidata Object Storage Repository.
Inserire il nome e la descrizione per il nuovo repository Object Storage e cliccare Next.
Nella finestra Account inserire https://s3.cubbit.eu oppure s3.[il-tuo-tenant].cubbit.eu se hai un tenant personalizzato, nel campo Service point e inserire il valore eu-west-1 nel campo region. Nel campo delle credenziali fare click sul bottone Add per aggiungere le access credentials.
Sul campo credentials premere il pulsante Add per aggiungere le credenziali di accesso; nella finestra di dialogo che si aprirà inserire Access key , Secret key nei rispettivi campi e premere OK
Prima di procedere ulteriormente sarà necessario aver creato almeno un Bucket tramite altri client S3 (ad esempio Amazon AWS CLI o Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu).
Attenzione: nel caso di backup su Object Storage via Veeam, deve essere evitato nel modo più assoluto, l'utilizzo di S3 Versioning senza attivazione di S3 Object Lock (immutabilità). Senza l'immutabilità infatti, vengono moltiplicate sia le operazioni necessarie alla cancellazione, sia lo spazio totale utilizzato, a totale svantaggio del cliente.
Dopo avere creato un nuovo bucket dalla Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu procedere adesso con la sezione Bucket.
Questa finestra permette, tramite il pulsante Browse più in alto (1), di navigare tra i bucket presenti sul vostro account S3 Cubbit. Dopo avere selezionato il bucket premere OK (2) e chiudere la finestra di dialogo.
Allo stesso modo, cliccando il pulsante Browse (3) più in basso, sarà possibile navigare tra le cartelle all'interno del bucket scelto o crearne una nuova (pulsante New folder).
Il bucket e la cartella scelti saranno la destinazione dei backup. Per andare avanti selezionare la cartella e premere OK. Successivamente premere il pulsante Apply (4).
Rivedere le informazioni e quindi cliccare Finish per completare questo step. Il repository Cubbit Object Storage S3 Compatible è stato aggiunto con successo su Veeam, sarà possibile utilizzarlo per alcune tipologie di backup job con Veeam.
Aggiungere il File Share (NFS)
Per aggiungere una risorsa NFS share, selezionare Inventory > File Shares e cliccare Add File Share.
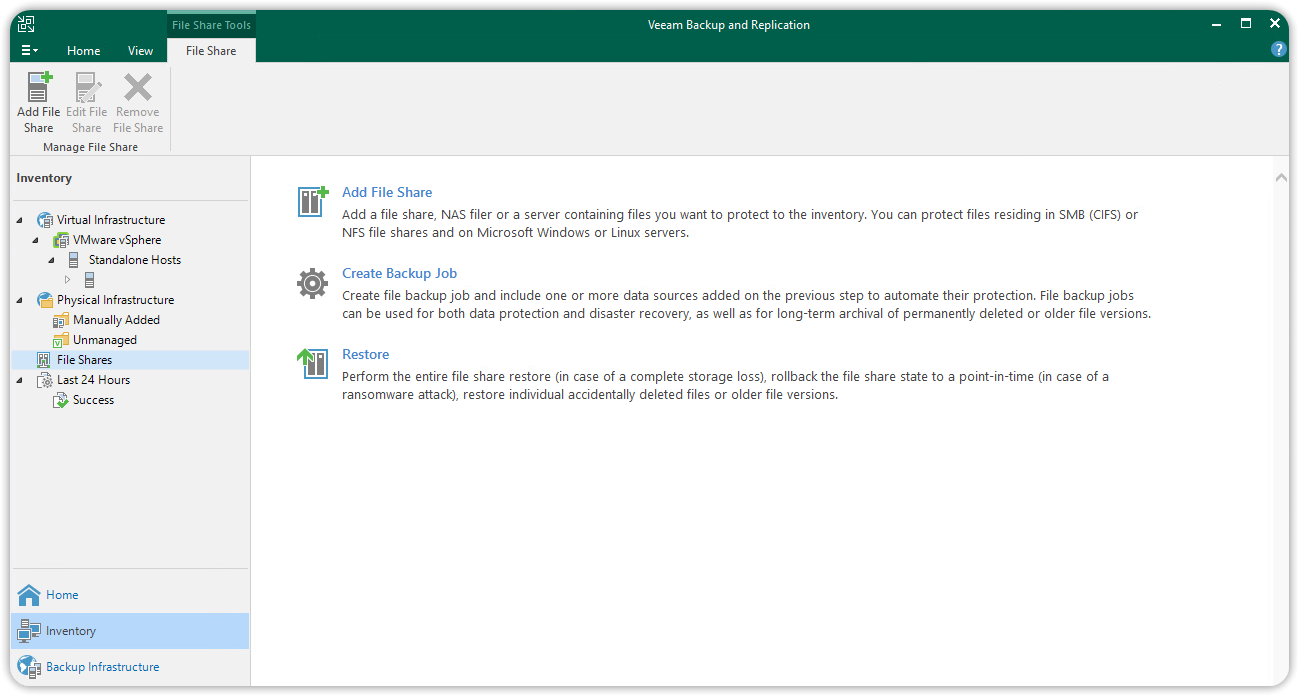
Nella finestra di dialogo Add File Share, selezionare NFS Share per continuare.

Nella sezione NFS File Share, aggiungere indirizzo IP e path verso la condivisione NFS <IP address>:/percorsodellacondivisione.
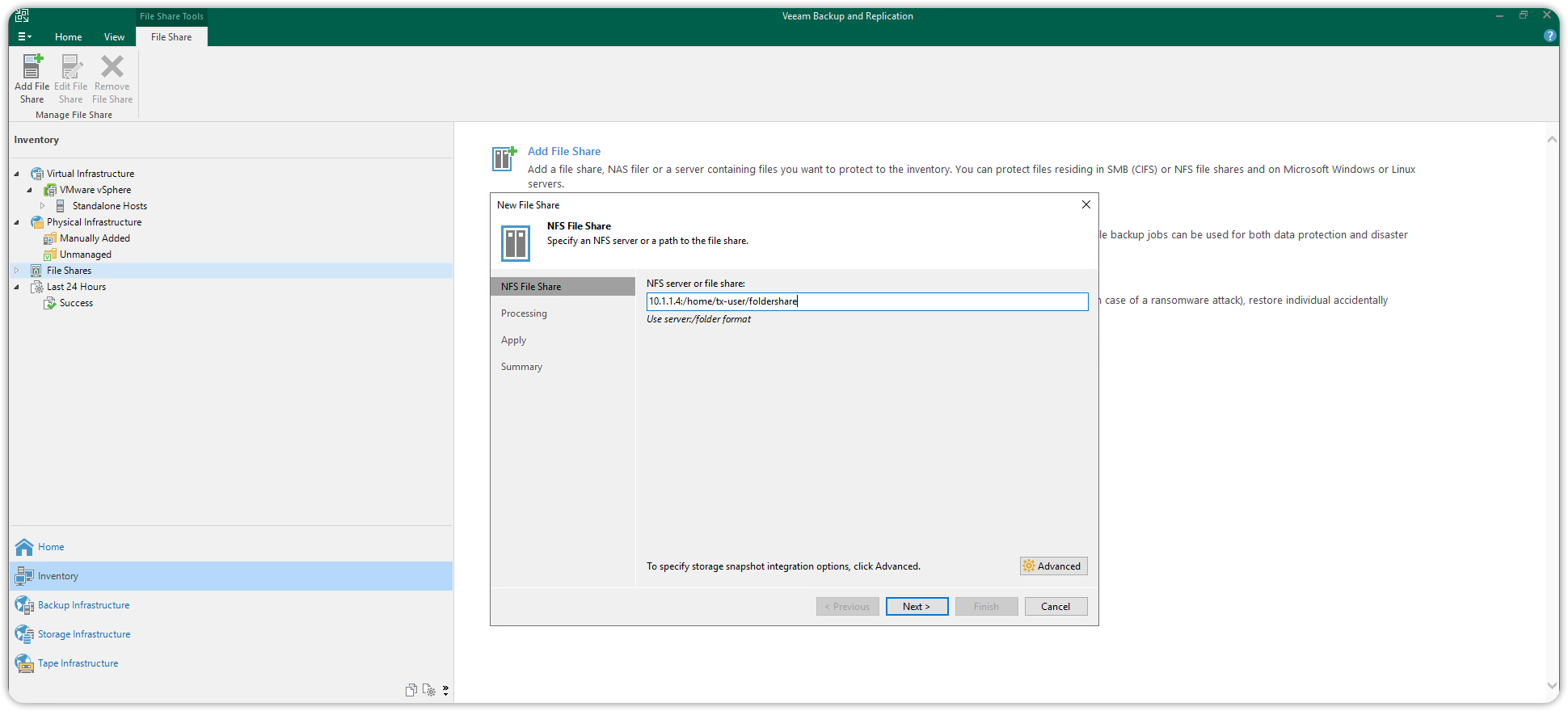
Assicurarsi che il Cache repository punti al Default Backup Repository (nello screenshot di seguito è stato rinominato configurationbackup), e cliccare Apply per aggiungere la risorsa di rete File Share NFS.
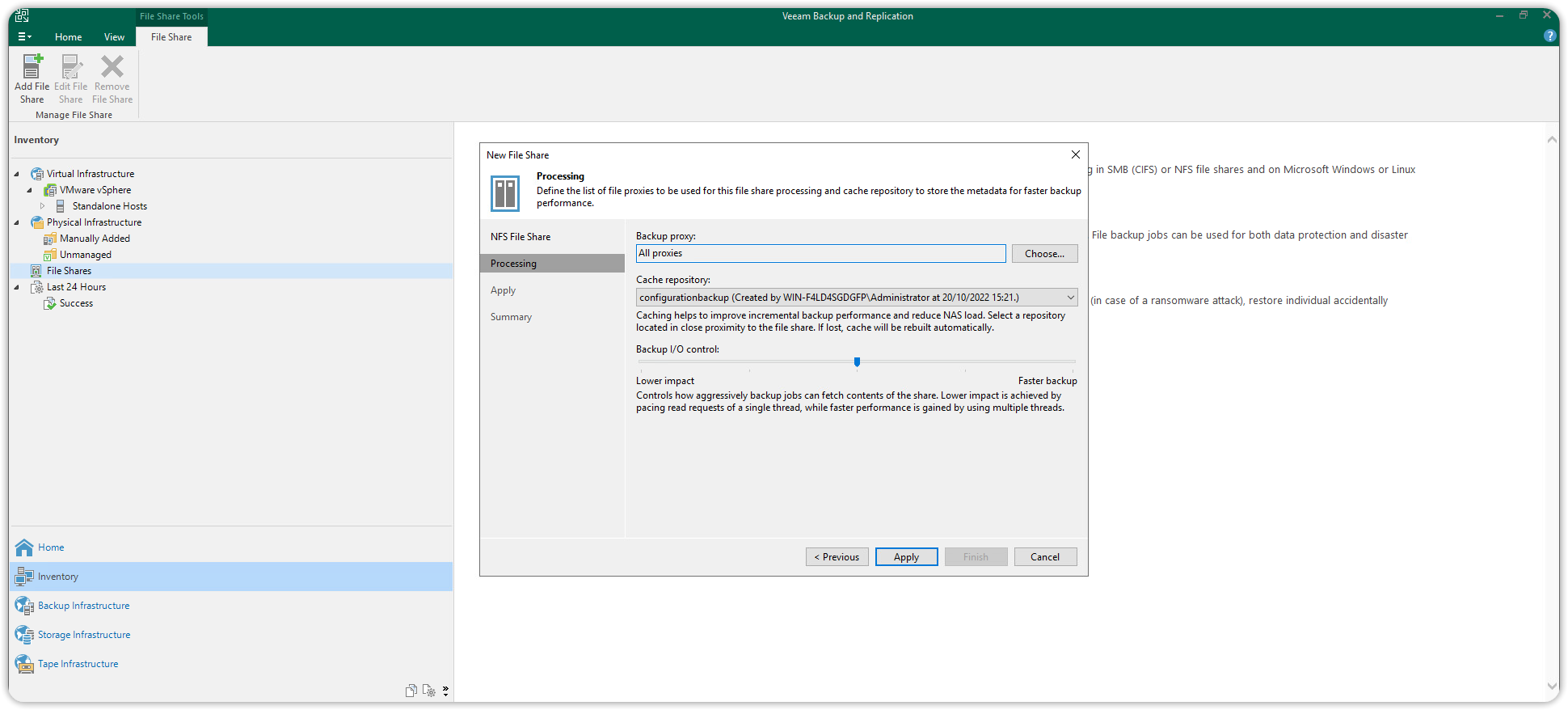
Poi premere Finish per chiudere il Wizard. La nuova risorsa File Share NFS sarà listata sotto File Shares > NFS Shares nella scheda Inventory.

Creare un Backup Job
A questo punto si può procedere con la creazione del Backup Job. Selezionare Home dal pannello di navigazione sulla sinistra, premere il pulsante in alto a sinistra Backup Job e poi selezionare File Share.
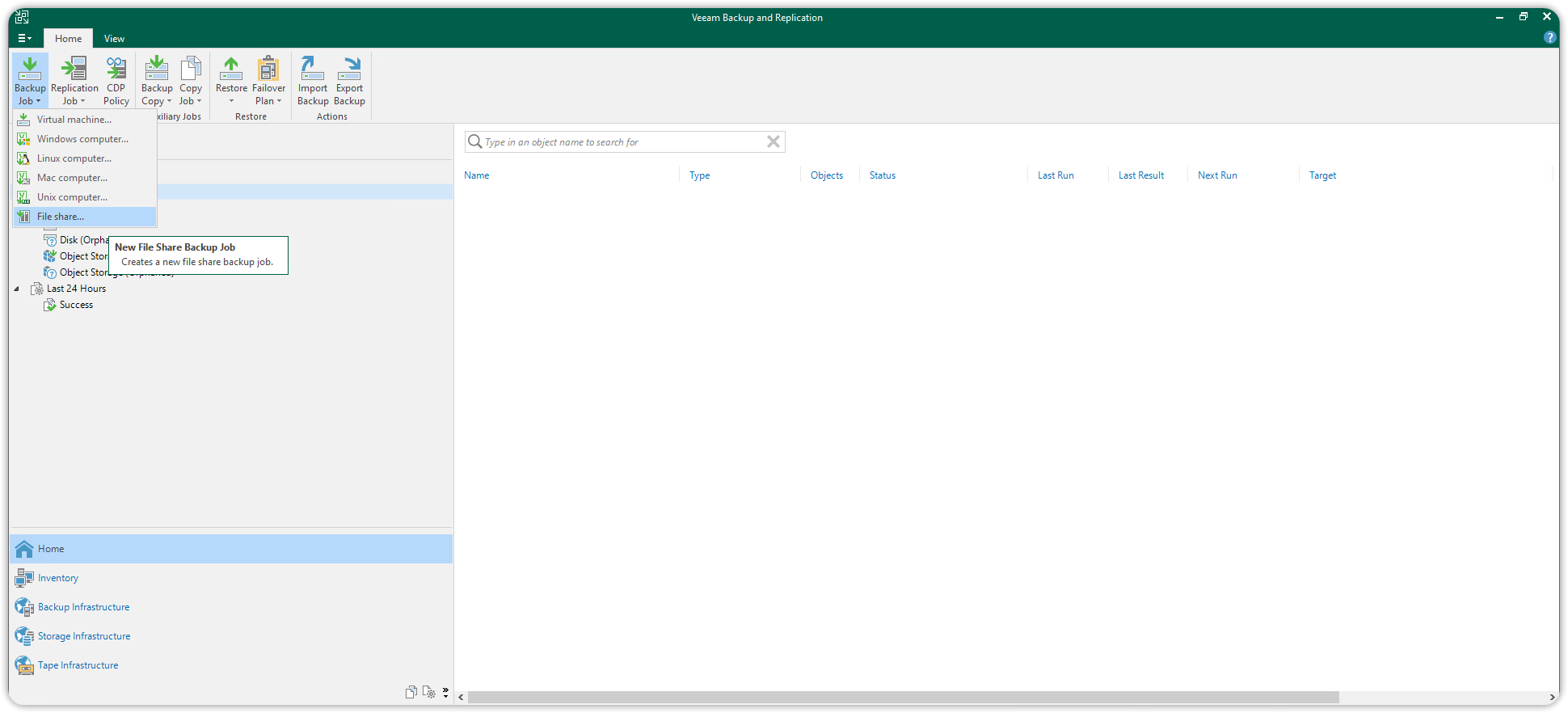
Si aprirà una procedura guidata che aiuterà nella creazione del Backup Job. Scegliere il nome del Backup Job ed il percorso dei file e cartelle di cui effettuare il backup.

Nella sezione Storage configurare come segue:
- Il Backup repository dove destinare i file.
- La durata per cui tenere le ultime versioni dei files in locale.
- Per quanto tempo mantenere le precedenti versioni sull’Archive repository Cubbit S3.
- L’Archive repository Cubbit S3 (come configurato precedentemente) dove archiviare le precedenti versioni dei file.
Premere Advanced in basso a destra per entrare nella configurazione avanzata.
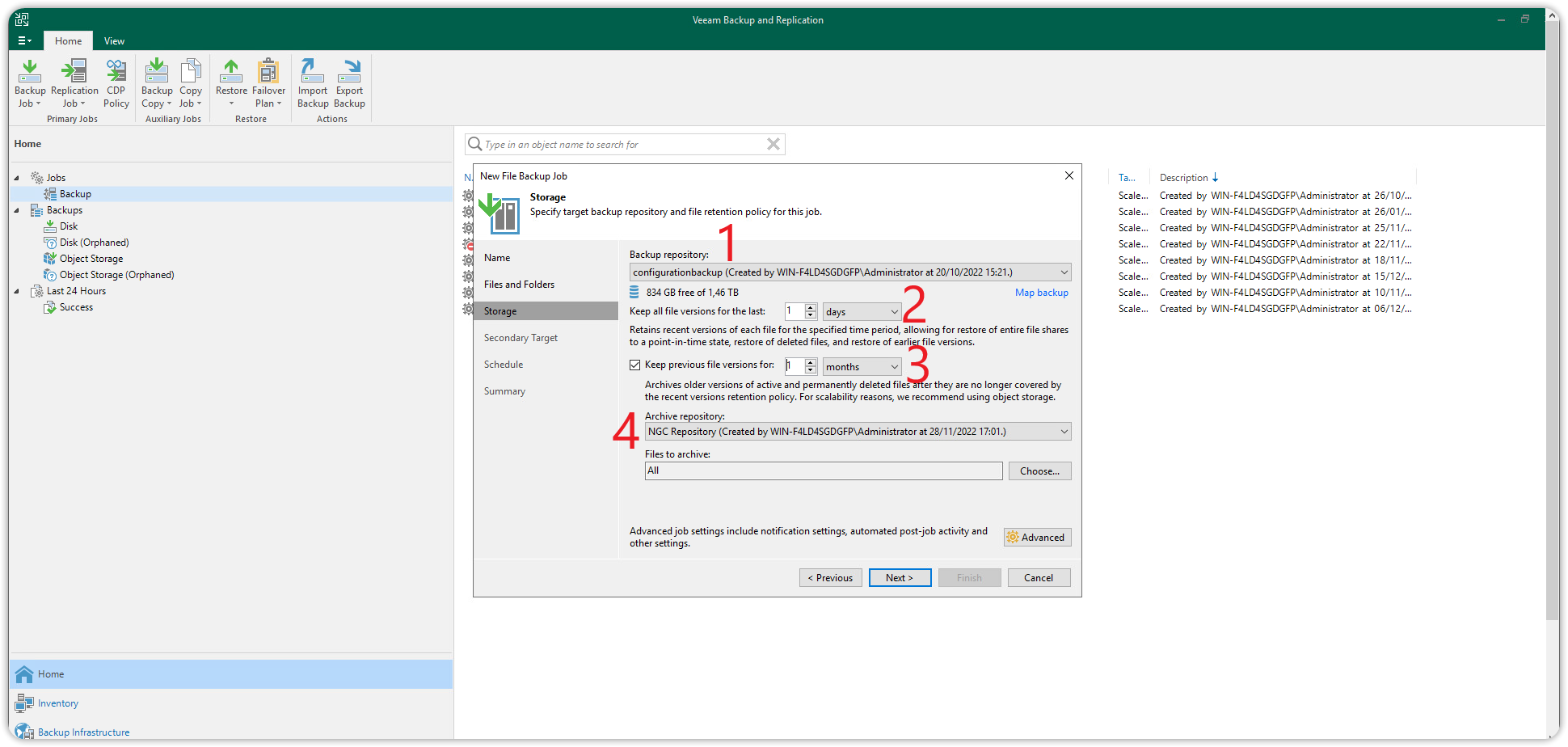
Selezionare la scheda Storage in alto e sotto Storage optimization: impostare il valore a 4MB e premere OK.
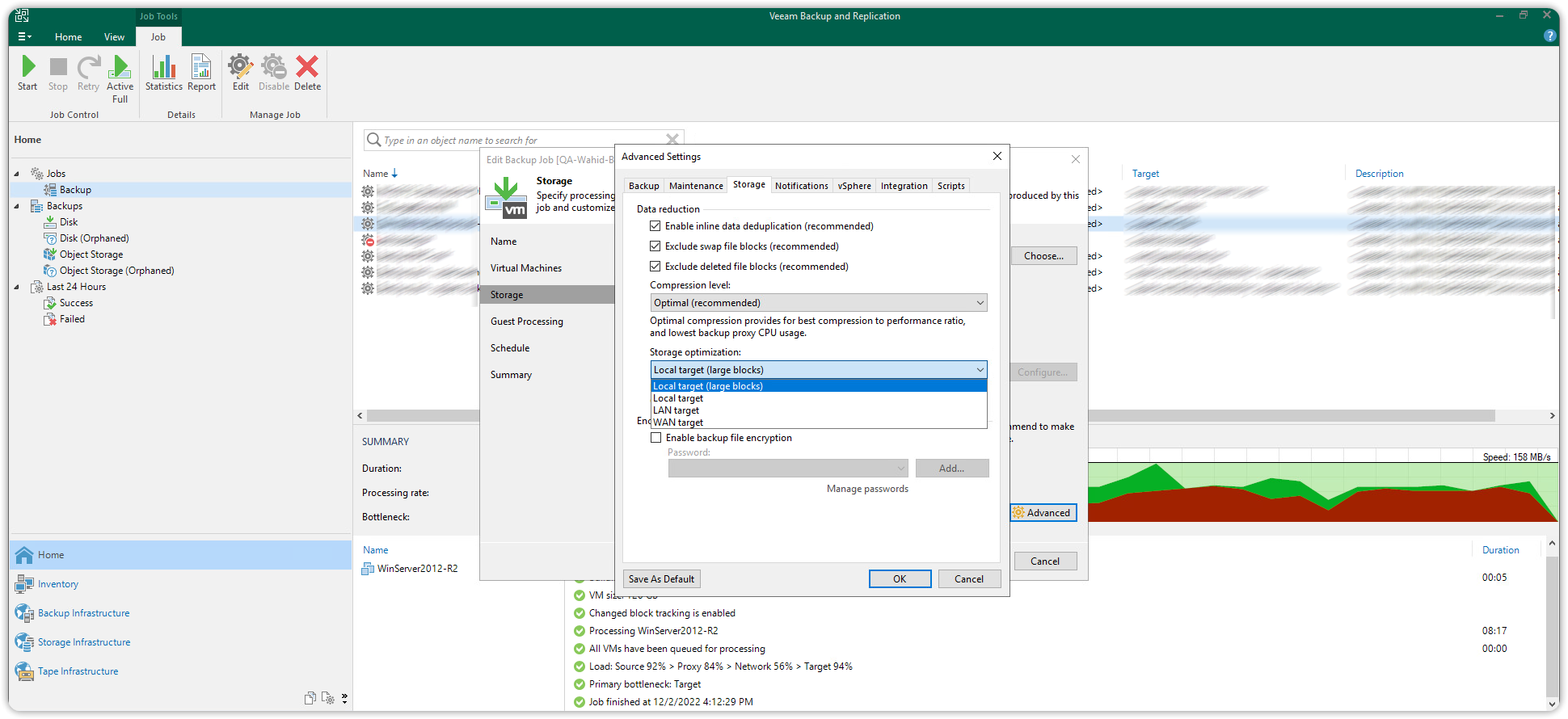
Nella sezione Secondary Target lasciare vuoto e premere Next. Nella sezione Schedule impostare la pianificazione di data e ora del Backup Job e premere Next. Verificare i dati inseriti nella sezione Summary e selezionare la casella se intendiamo far partire immediatamente il Backup Job appena creato. Infine cliccare su Apply
Il Backup Job sul File Share (NFS) sarà aggiunto alla lista dei Jobs disponibili di Veeam ed eventualmente avviato direttamente.
Per maggiori informazioni sull'utilizzo di Veeam Backup & Replication 12 potete consultare la documentazione ufficiale.
Scale-out backup
Veeam Scale-Out Backup supporta file server, macchine virtuali e backup fisici. Per consentire la scalabilità per l'archiviazione dei dati a più livelli, è necessario un repository Scale-out per le macchine virtuali e altri backup.
Questo tipo di sistema di repository fornisce un supporto di scalabilità orizzontale per l'archiviazione multi-livello dei dati. E' possibile utilizzare uno o più repository di backup per estenderne un altro. Generalmente un repository object-storage S3 Compatible è usato come estensione di un repository locale basato su dischi (primario).
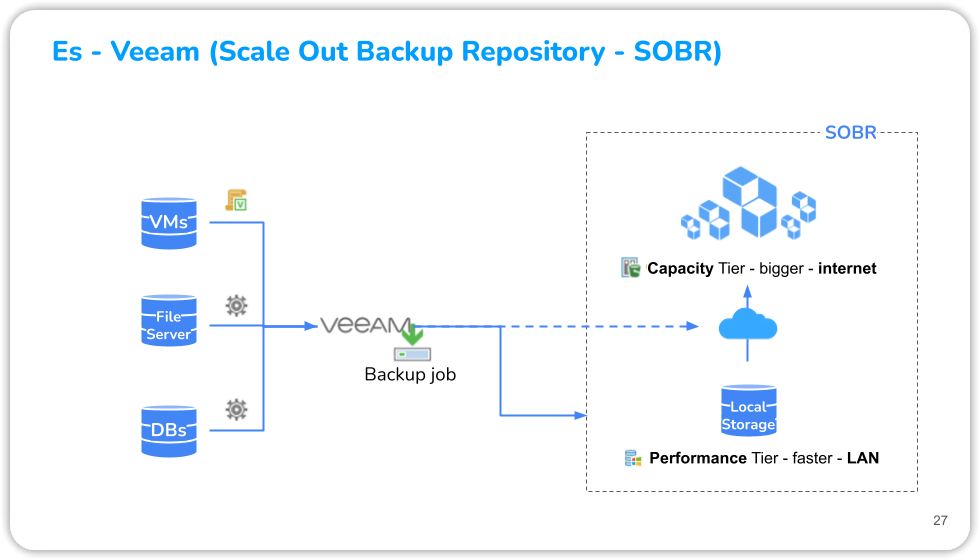
Di seguito sono illustrati i passaggi per creare una configurazione di questo tipo.
Requisiti per Scale-out backup
Per prima cosa, è necessario ottenere access key e secret key dalla Cubbit Web Console oppure https://console.[il-tuo-tenant].cubbit.eu. Si possono seguire queste istruzioni su come iniziare con un account Cubbit e generare queste chiavi.
Per procedere nella configurazione è necessario disporre di:
- Software Veeam Backup and Replication (Versione 11 o successive)
- Licenza Veeam Universal License (VUL) o Per-socket (Enterprise Plus o superiore)
- Ambiente di virtualizzazione (es. VMware)
Le Community e Standard editions di Veeam Backup and Replication 12 non permettono di utilizzare la funzionalità di backup diretto (ENHANCED Object storage). In questo caso il repository S3 compatibile è chiamato Capacity Tier, mentre quello locale è chiamato Performance Tier. La versione VUL ed Enterprise Plus non hanno limitazioni riguardo il massimo numero di repository o estensioni.
Scale-out Backup Repository (Capacity tier)
Dalla vista Backup Infrastructure, click destro su Backup Repositories e scegliere Add Backup Repository.
Dalla finestra Add Backup Repository, scegliere Object Storage.
Scegliere S3 compatible object storage per avviare la procedura guidata Object Storage Repository.
Inserire il nome e la descrizione per il nuovo repository Object Storage e cliccare Next.
Nella finestra Account inserire https://s3.cubbit.eu oppure s3.[il-tuo-tenant].cubbit.eu se hai un tenant personalizzato, nel campo Service point e inserire il valore eu-west-1 nel campo region. Premere Next per continuare. Nella finestra di dialogo che si aprirà inserire la Access key e la Secret key nei rispettivi campi e premere OK.
Prima di procedere ulteriormente sarà necessario aver creato almeno un Bucket tramite altri client S3 (ad esempio Amazon AWS CLI o Cubbit Web Console).
Attenzione: nel caso di backup su Object Storage via Veeam, deve essere evitato nel modo più assoluto, l'utilizzo di S3 Versioning senza attivazione di S3 Object Lock (immutabilità). Senza l'immutabilità, infatti, vengono moltiplicate sia le operazioni necessarie alla cancellazione, sia lo spazio totale utilizzato, a totale svantaggio del cliente.
Dopo avere creato un nuovo bucket dalla Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu procedere adesso con la sezione Bucket.
Questa finestra permette, tramite il pulsante Browse più in alto (1), di navigare tra i bucket presenti sul vostro account S3 Cubbit. Dopo avere selezionato il bucket premere OK (2) e chiudere la finestra di dialogo.
Allo stesso modo, cliccando il pulsante Browse (3) più in basso, sarà possibile navigare tra le cartelle all'interno del bucket scelto o crearne una nuova (pulsante New folder).
Il bucket e la cartella scelti saranno la destinazione dei backup. Per andare avanti selezionare la cartella e premere OK. Successivamente premere il pulsante Apply (4).
Rivedere le informazioni e finalmente cliccare Finish per completare questo step. Il repository Cubbit Object Storage S3 Compatible è stato aggiunto con successo su Veeam, sarà possibile utilizzarlo per alcune tipologie di backup job con Veeam.
SOBR Performance tier (Repository Primario)
Da VMware vCenter (o dal client VMware Workstation), cliccare col pulsante destro sul server Veeam e selezionare Edit Settings. Cliccare su Add hard disk e selezionare un hard disk dalla lista a cascata.
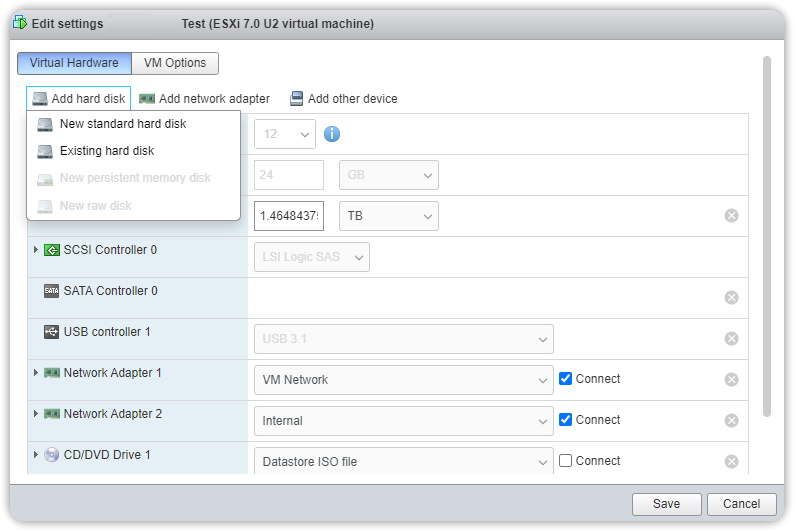
La capacità di questo hard disk dovrà essere sufficiente per ospitare i dati di backup primario (bisogna fare attenzione al fatto che Veeam full backup produce file che non hanno una dimensione pari al backup stesso). Rivedere le modifiche e premere Finish.
Su Veeam Backup & Replication aprire la sezione Backup Infrastructure cliccare su Backup Repository e poi cliccare Add Repository. Nella finestra che si aprirà selezionare la tipologia di connessione del repository primario Direct attached storage (in questo caso un disco direttamente connesso a server Microsoft Windows o Linux).
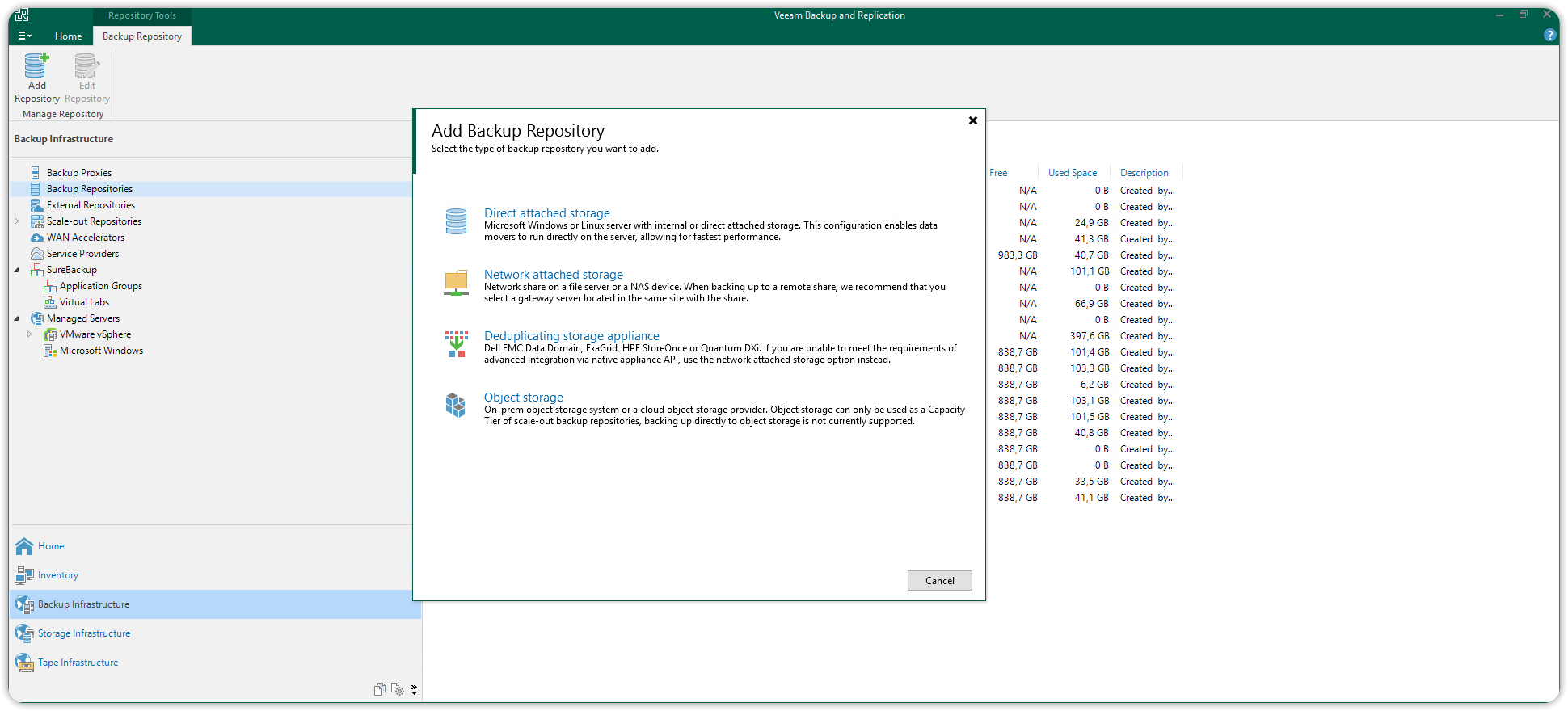
Scegliere un nome ed una descrizione per il nuovo repository primario e cliccare Next. Si aprirà una finestra di dialogo, nella sezione Server premere Populate e potrete scegliere come target del vostro repository primario il disco che preferite.
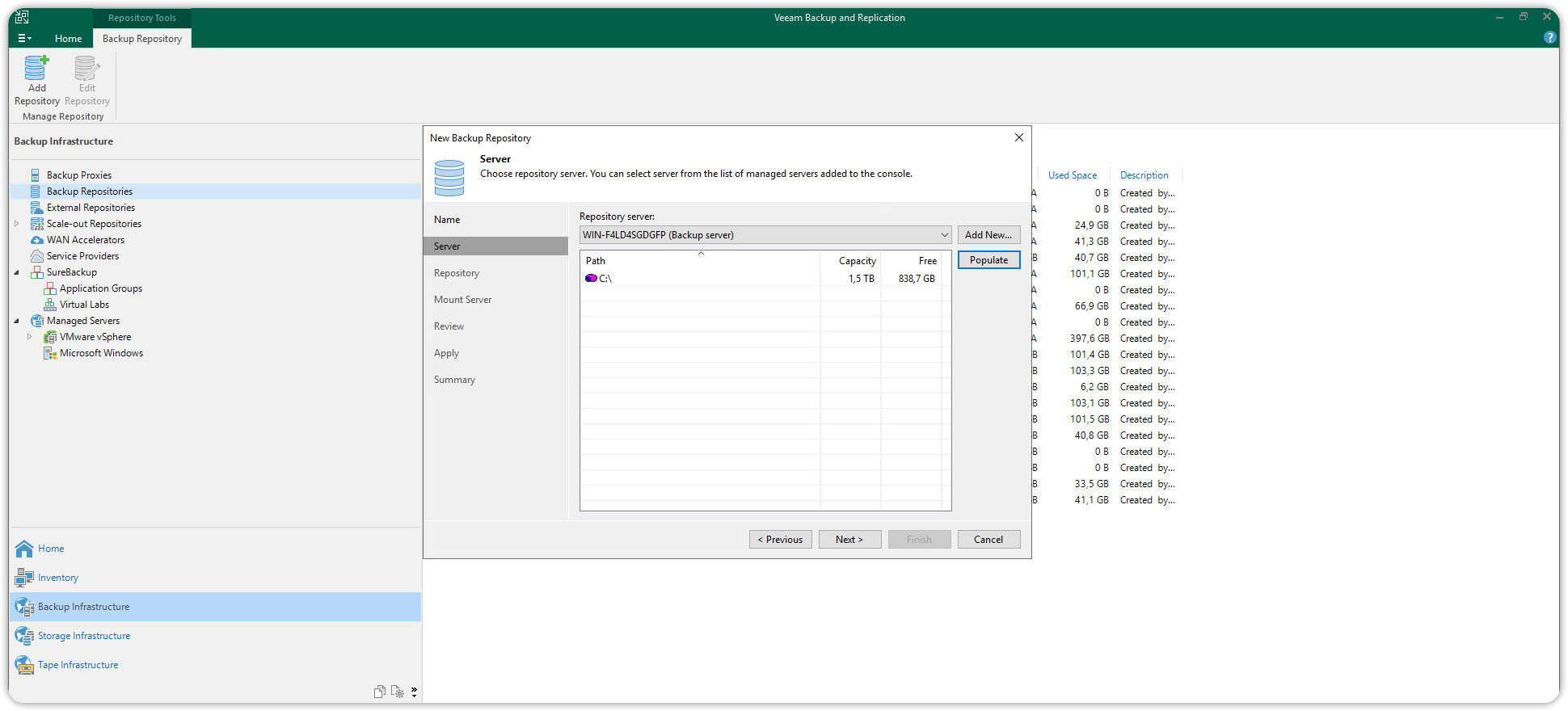
Nella sezione Repository disattivare l’opzione Limit maximum concurrent tasks, per consentire più operazioni simultanee.
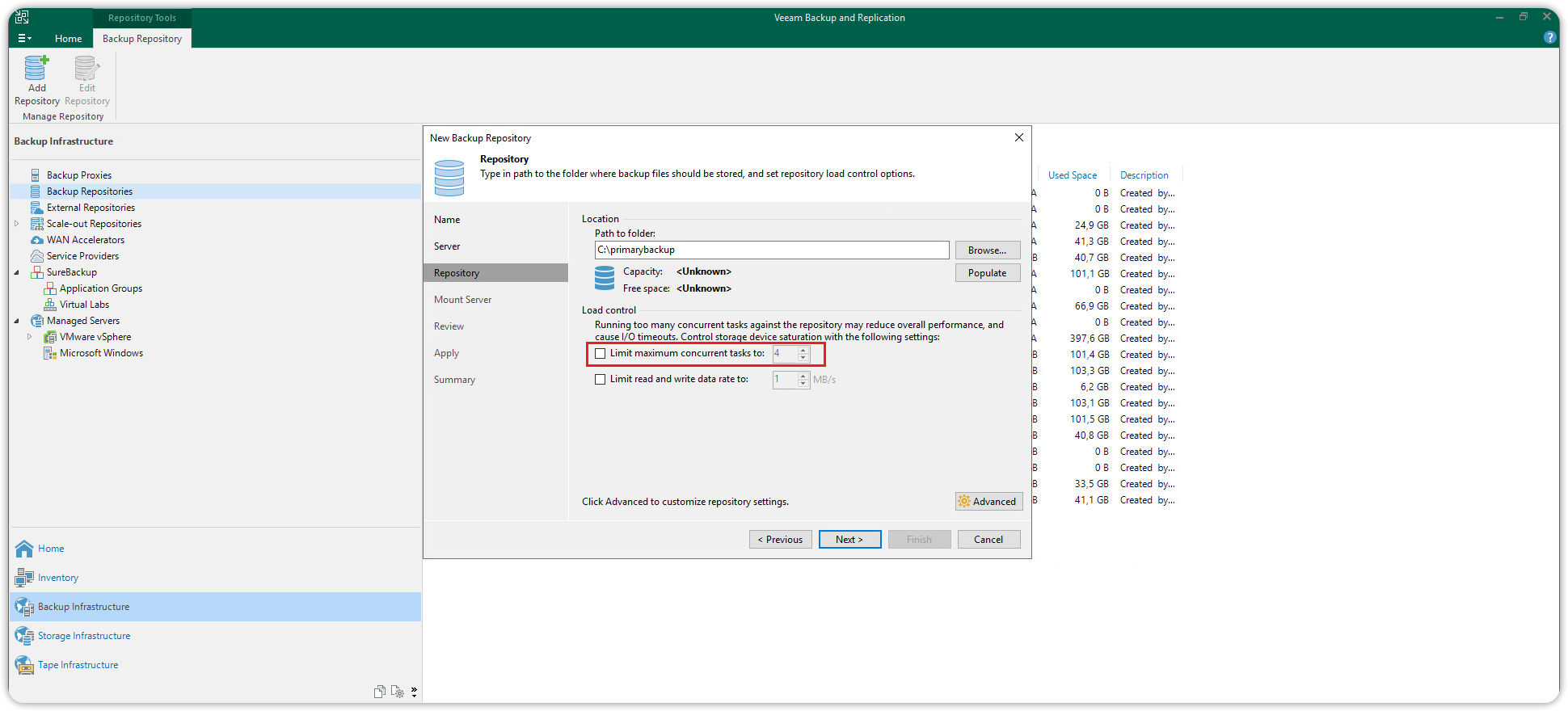
Cliccare poi su Next fino a chiudere l'intera procedura guidata.
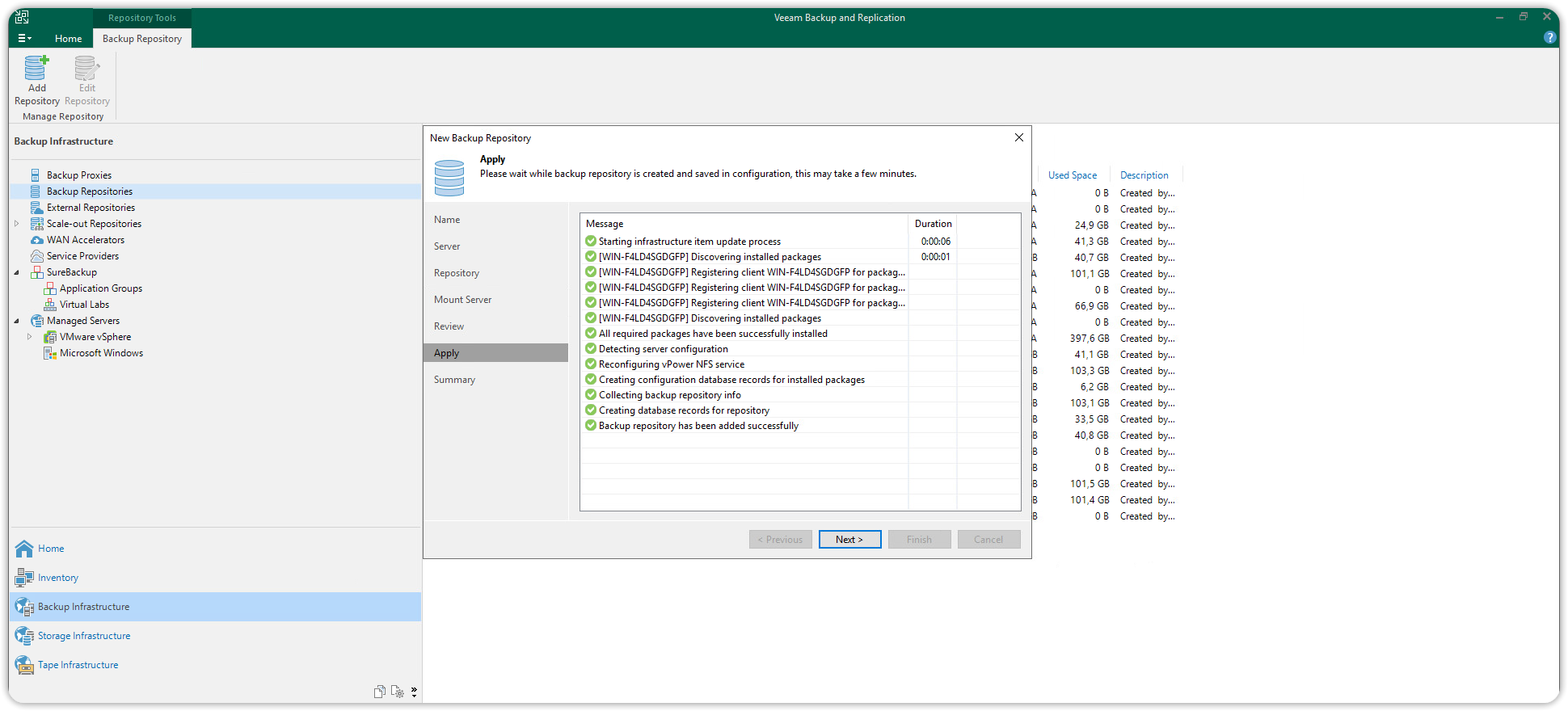
Scale-out Repository
A questo punto abbiamo sia il Performance Tier, che il Capacity Tier (Cubbit S3 Object Storage) necessari alla definizione dello Scale-out.
Selezionare nuovamente Backup Infrastructure, cliccare su Scale-out Repositories e cliccare su Add Scale-out Repository.
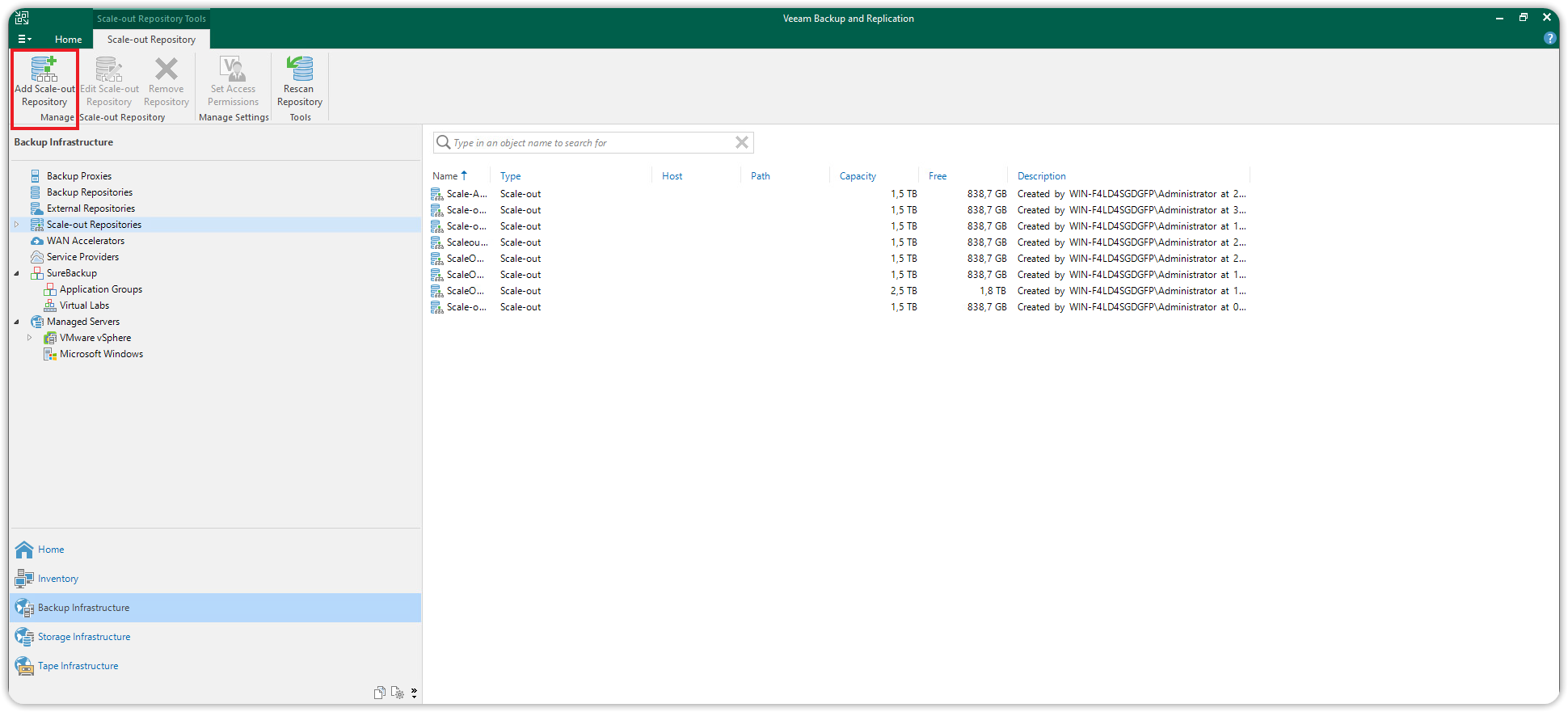
Inserire il nome e la descrizione per questo nuovo Scale-out Repository. Cliccare Next per continuare. Nella sezione Performance Tier che si aprirà, cliccare su Add... .
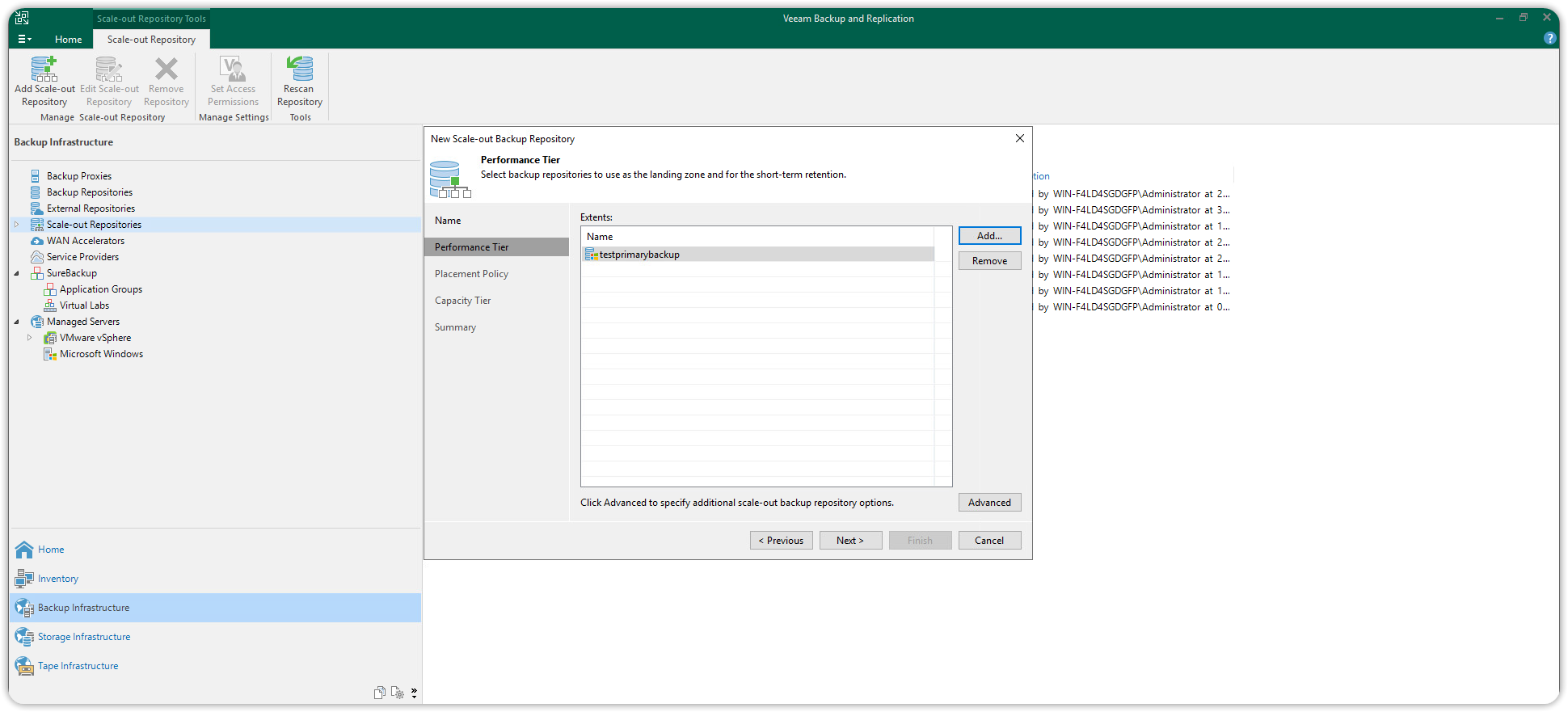
Sempre nella stessa finestra di dialogo Performance Tier cliccare poi su Advanced per visualizzare le opzioni avanzate del Performance tier e deselezionare Use per-machine backup files e premere OK. Deselezionare Use per-machine backup files e premere OK. Cliccare poi Next per continuare.
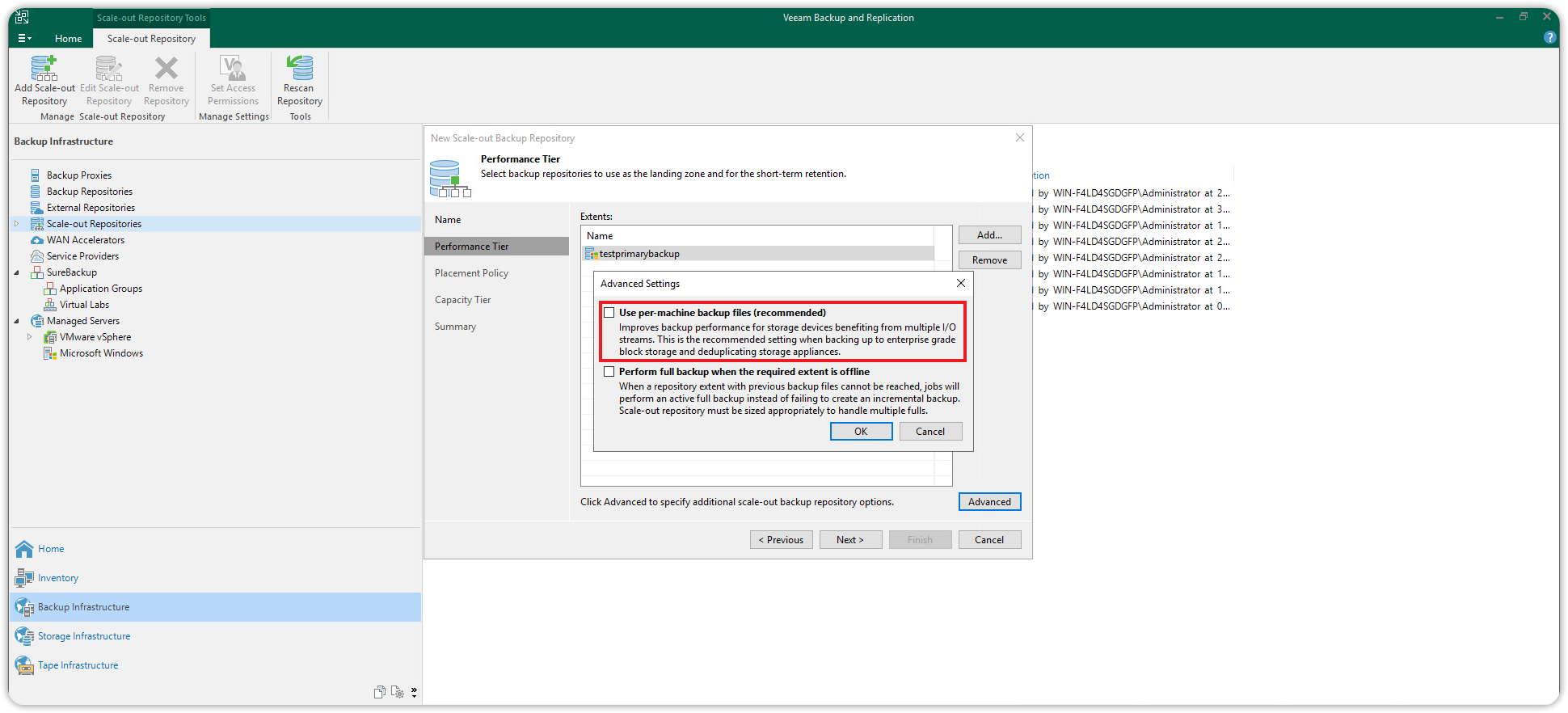
Nella sezione Placement Policy, mantenere la Data Locality policy di default. Questa policy consente di allocare tutti i files (full ed incrementali) nella stessa estensione. Poi cliccare Next per procedere.
Nella sezione Capacity Tier, selezionare la casella Extend scale-out backup repository capacity with object storage e dal menù a tendina selezionare il Repository di Cubbit S3 object storage (il Capacity Tier creato precedentemente).
Selezionare la casella la cui descrizione comincia per Copy backups to object storage as soon as..., questo sposterà i backup in cloud immediatamente dopo la loro creazione. Selezionare o deselezionare la casella la cui descrizione inizia con Move backups to object storage as they age out..., in base alle specifiche necessità. basato sui need specifici dell'utente.
Infine premere su Apply per applicare i cambiamenti.
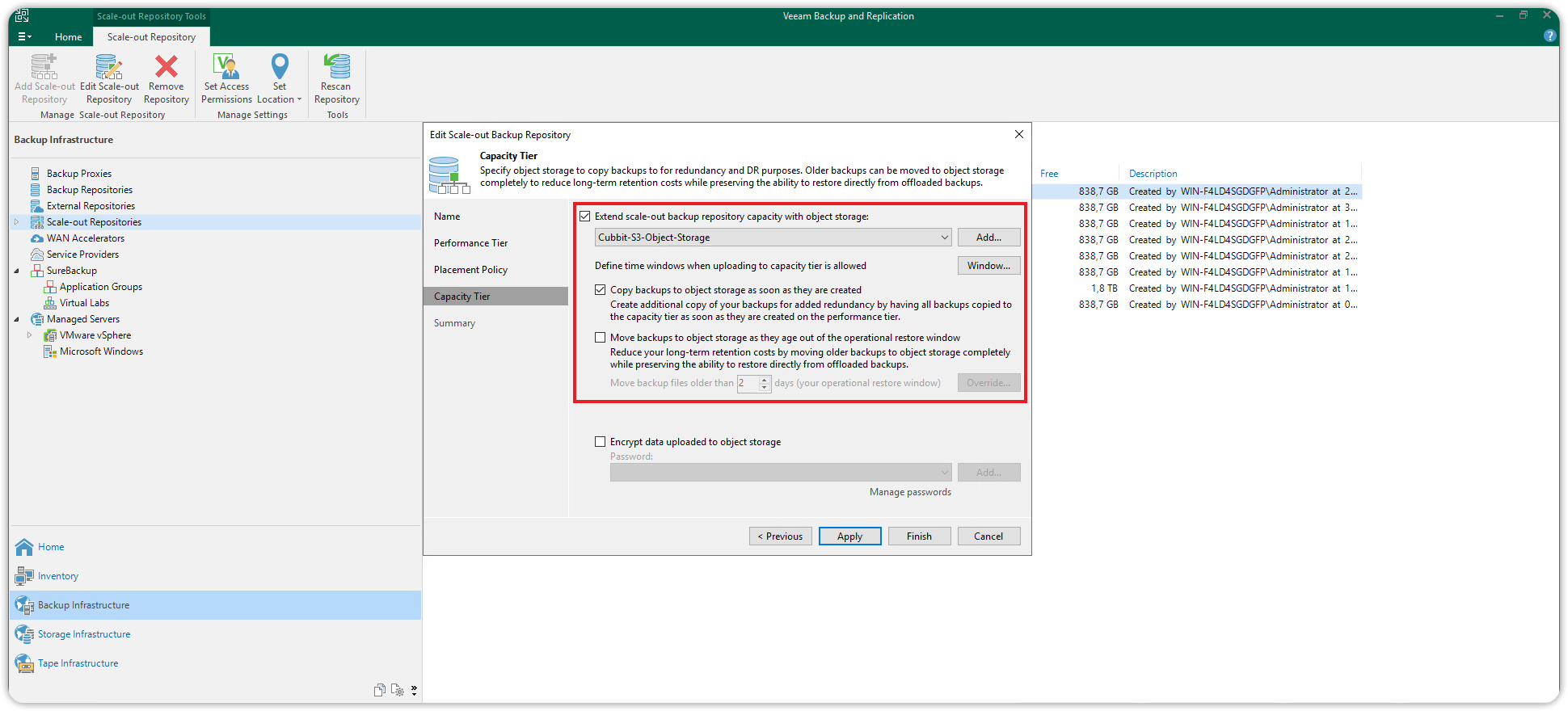
Nella sezione Summary rivedere la lista dei cambiamenti applicati e premere Finish per completare la procedura guidata di creazione dello Scale-out Repository.
Sarà possibile visualizzare lo Scale-out Repository appena creato dalla sezione Backup Infrastructure su Scale-out Repositories.
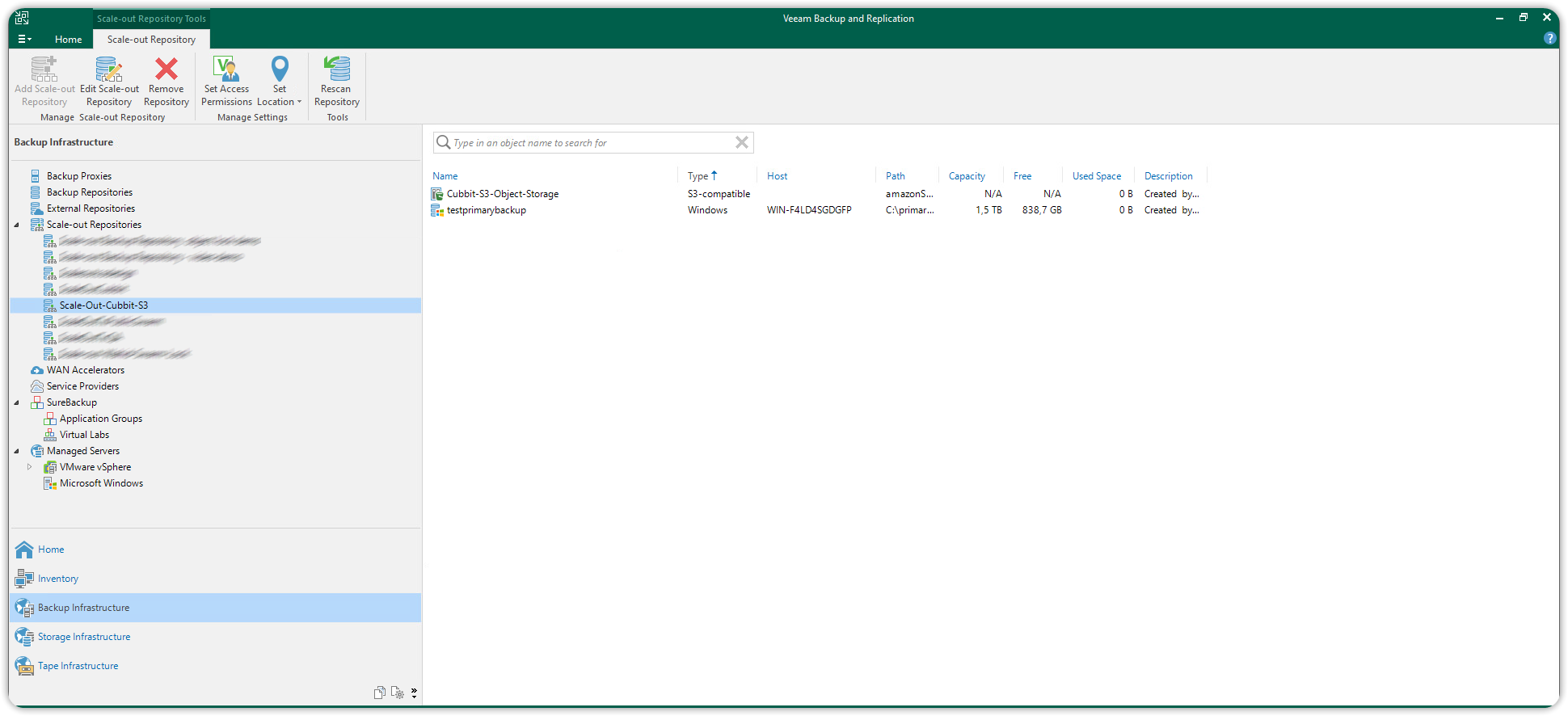
Lo Scale-out Repository appena creato sarà disponibile come target-repository in qualsiasi Backup Job che verrà creato d'ora in avanti.
Per maggiori informazioni sull'utilizzo di Veeam Backup & Replication visita la documentazione ufficiale
Cubbit Virtual NAS Gateway
Questa guida ha lo scopo di descrivere la configurazione di un ambiente che consenta di eseguire un backup tramite Veeam direttamente sul cloud Cubbit utilizzando l’immagine di una macchina virtuale preconfigurata.
Cubbit fornirà, sotto forma di file OVA, l’immagine di una macchina virtuale preconfigurata, cui dovranno essere date le seguenti risorse:
- 2x vcpu
- 4GB Ram
- 100 GB HDD - le performance migliori si hanno quando l'hard disk della VM riesce a contenere un full-backup per intero.
Di seguito lo schema architetturale della soluzione proposta:
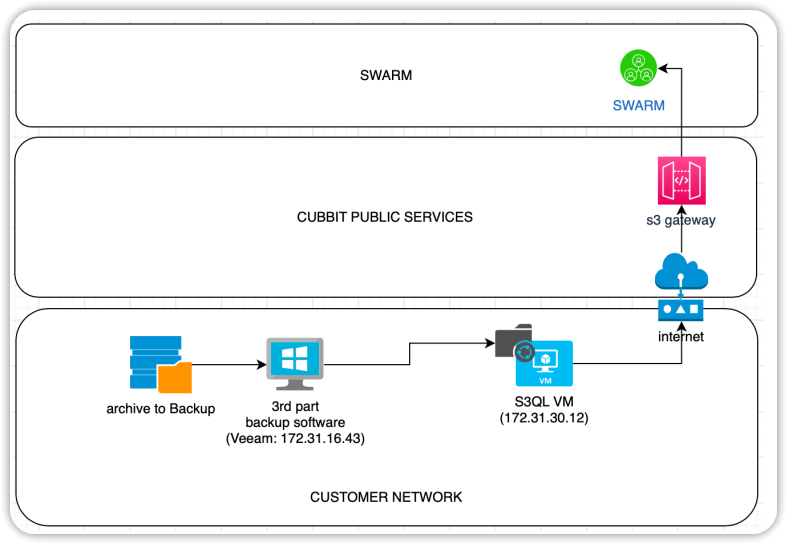
Si noti che, la VM ngc-s3gw è all’interno della LAN aziendale, ed è quindi in grado di accogliere i backup ad una velocità molto elevata. E' possibile che la banda di upload verso internet non sia altrettanto performante: in questo caso la VM dovrà essere in grado di immagazzinare temporaneamente i dati, in attesa che la coda di dati verso internet si smaltisca. La VM è dotata a tal fine di una cache disco. Suggeriamo di configurare il disco della VM con una capacità pari alla somma della grandezza dei full-backup che possono esservi contemporaneamente caricati.
Per favore, prima di continuare con questa procedura, installa e configura Cubbit Virtual NAS.
Collega Cubbit Virtual NAS a Veeam
La cartella condivisa /mnt/cubbit, può essere adesso configurata come un qualsiasi backup repository Linux di Veeam. Scegliere Add Backup Repository e selezionare l'opzione Network attached storage:
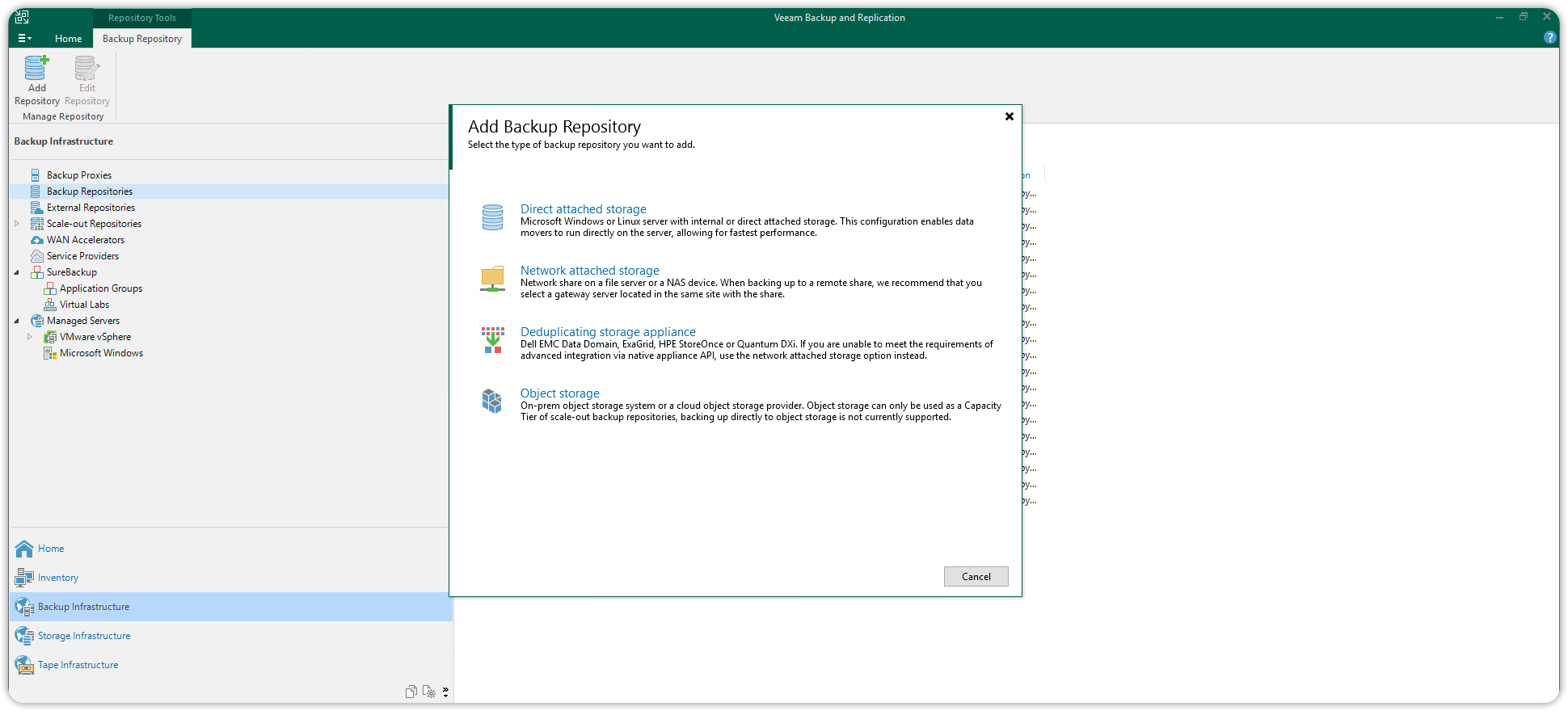
Scegliere NFS Share.
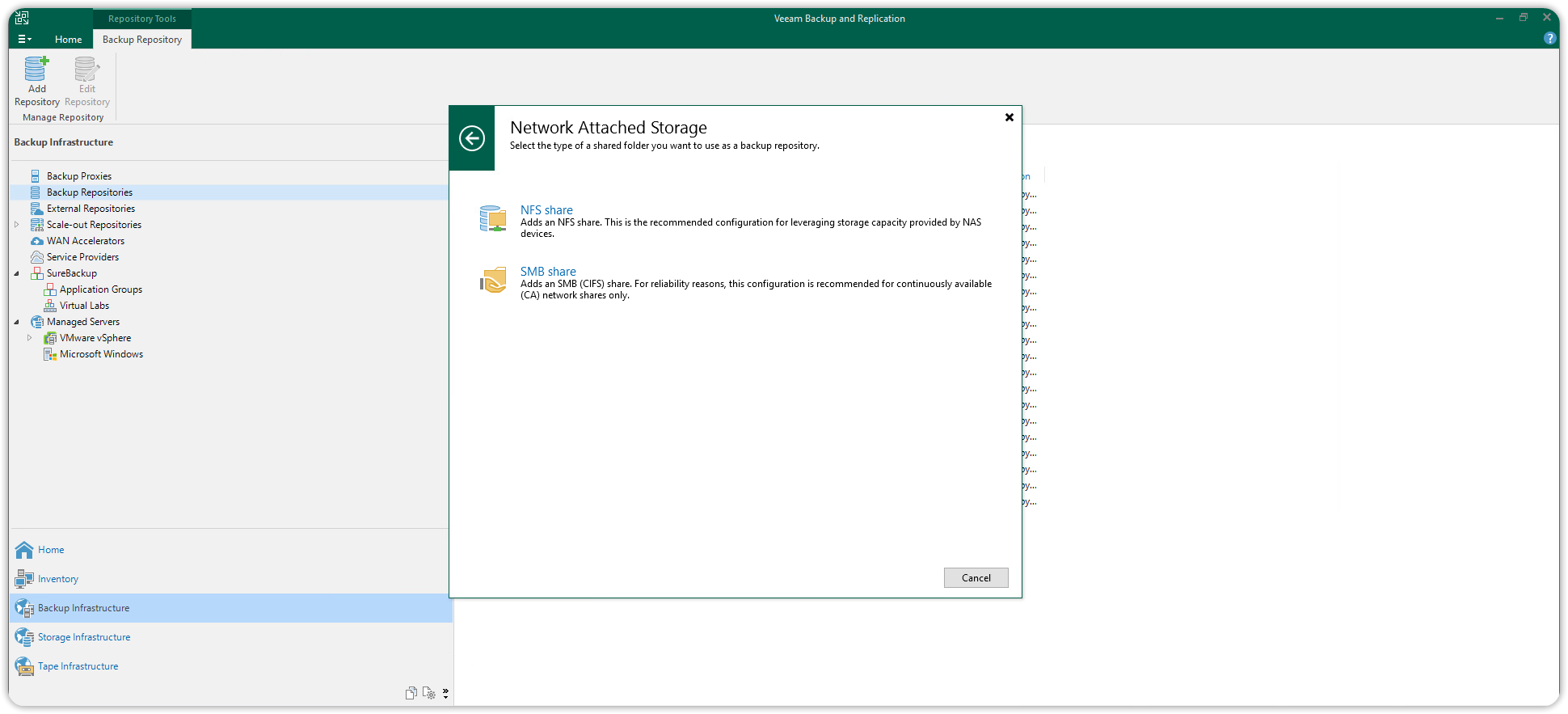
E subito dopo un nome per il nuovo repository, quindi premere Next.
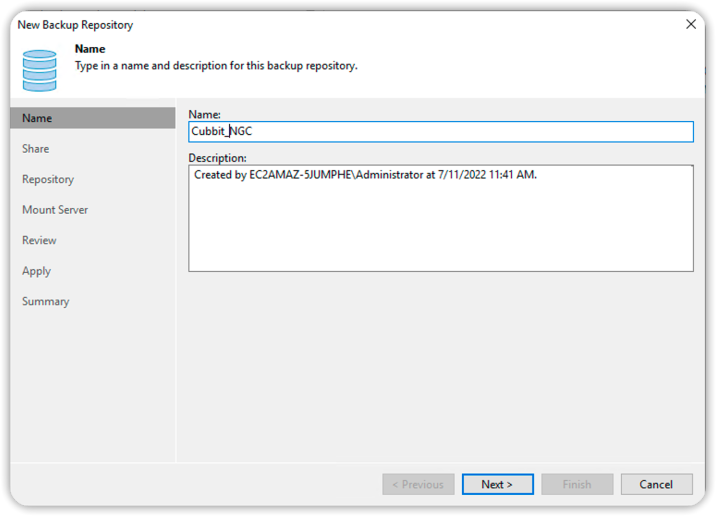
Immettere l'IP e il percorso della Share NFS creata in precedenza, quindi premere Next.
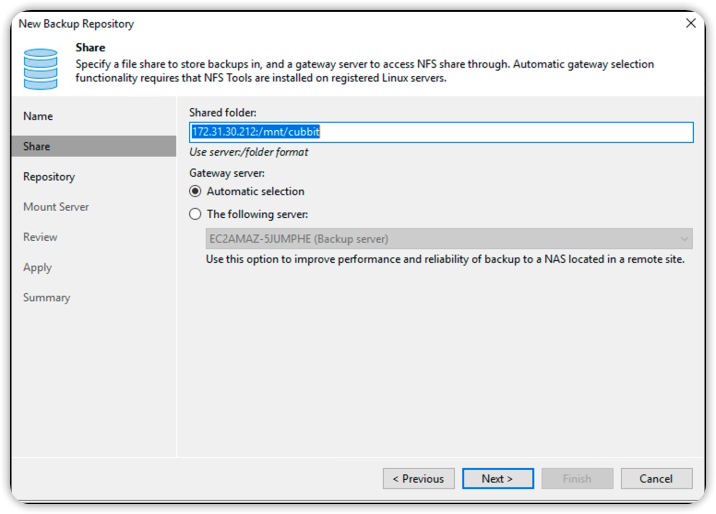
Nella sezione Repository, configurare come mostrato nell'immagine sottostante e premere Next.

Continua confermando le configurazioni di default fino alla fine del wizard, poi fare click su Finish.
Il repository compare tra quelli selezionabili per qualsiasi tipo di backup.
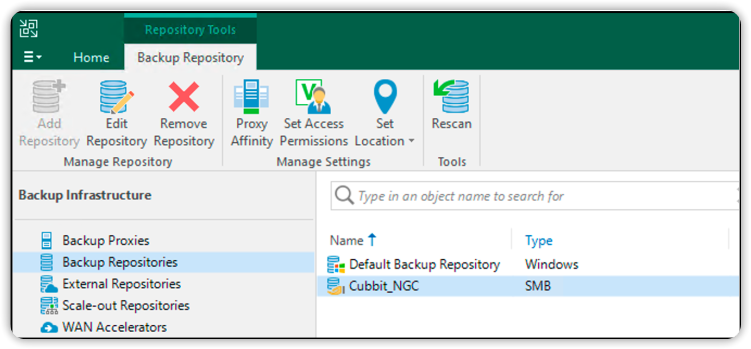
Per poterlo utilizzare sarà sufficiente scegliere il repository Cubbit, come Backup repository di un qualsiasi Backup job (nella sezione Storage).
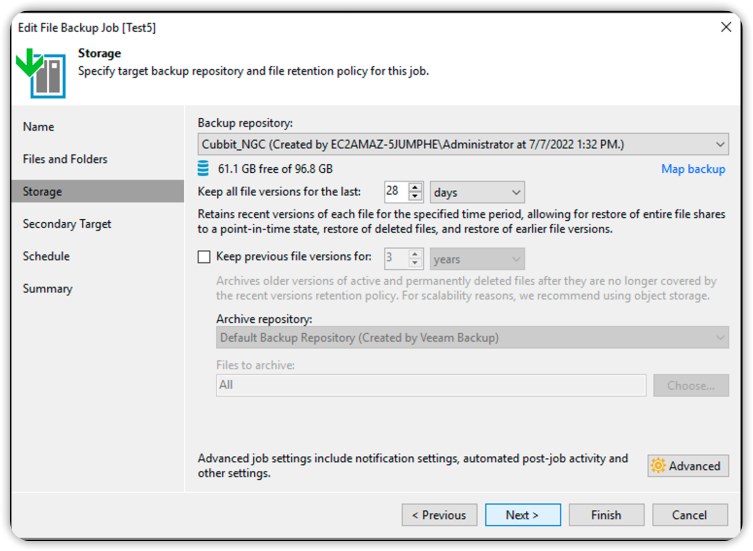
Per maggiori informazioni sull'utilizzo di Veeam Backup & Replication potete consultare la documentazione ufficiale.
Rimuovere un backup di Veeam per eliminare un bucket
Per poter rimuovere un bucket che contiene dei backup di Veeam è prima necessario svuotare completamente il bucket e questo può essere fatto con l'aiuto della funzione "Delete from Disk" di Veeam. Utilizzo
Delete from Disk funziona solo nel caso di bucket con S3 Versioning disabilitato o se il Backup Repository ha sempre avuto l'Immutabilità abilitata fin dall'inizio.
Se il bucket ha S3 Versioning sospeso o abilitato ma il repository non ha l'Immutabilità, Delete from Disk aggiungerà solo dei Delete Marker senza svuotare il bucket. In questo caso, leggi l'articolo sul nostro Help Center sulla cancellazione dei bucket per trovare un metodo alternativo.
Prima di procedere, se il Backup Repository è immutabile, suggeriamo di modificare le proprietà del repository per impostare l'immutabilità di Veeam ad un solo giorno. Non disattivare l'Immutabilità.
Per eliminare un backup dal repository Cubbit usando Veeam vai in Home, Backups ed espandi il Backup Job per vedere tutte le macchine virtuali al suo interno. Quindi clicca col tasto destro su una singola VM e scegli l'opzione Delete from Disk come mostrato nell'immagine seguente.
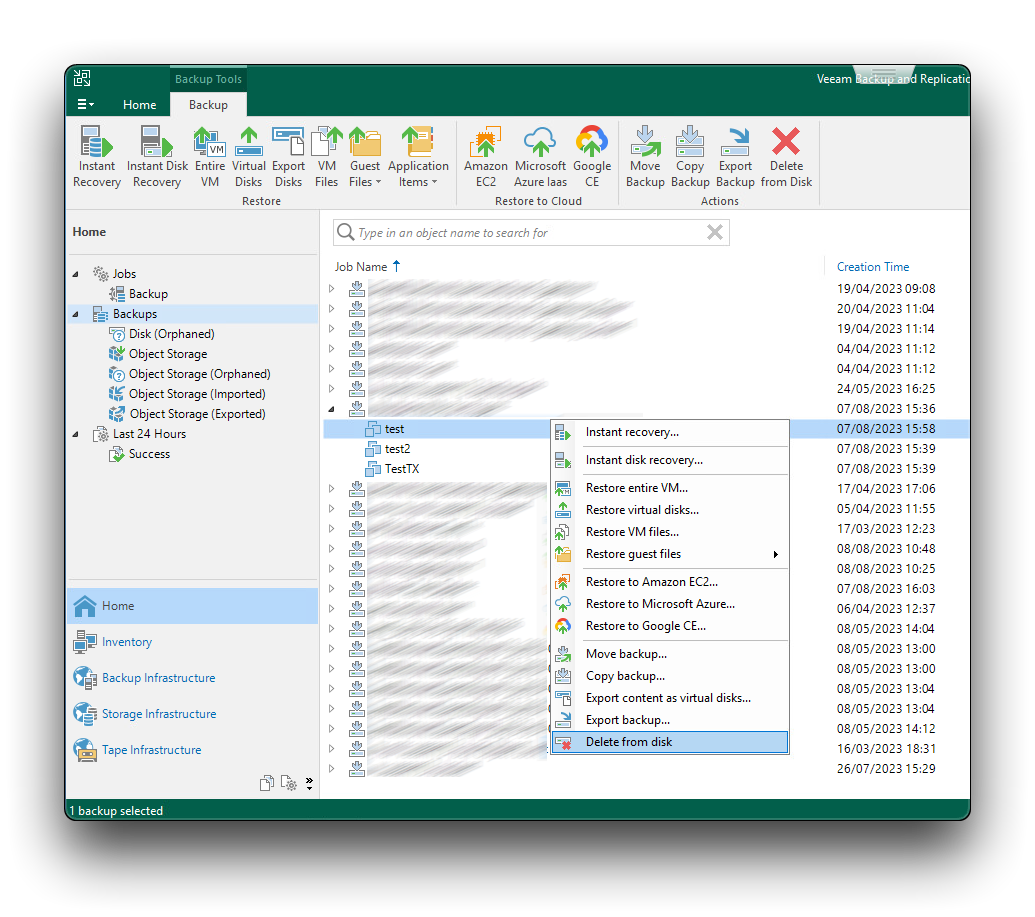
Dopo che il processo è stato completato per tutte le macchine virtuali contenute nel bucket, rimuovi ogni repository di Veeam che punta allo stesso bucket. Infine, puoi usare la Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu o qualsiasi altro client S3-compatible per svuotare il bucket dagli oggetti rimanenti per poi rimuoverlo definitivamente.
Dopo la cancellazione, se il Backup Repository era immutabile, sarà necessario attendere 10 giorni aggiuntivi prima di svuotare e rimuovere il bucket usando la Cubbit Web Console o console.[il-tuo-tenant].cubbit.eu o qualsiasi altro client S3-compatibile. Creare un bucket su Cubbit Web Console con S3 Object Lock attivo