Che cos'è uno Swarm?
Un Swarm è un layer di storage geo-distribuito, modulare e scalabile composto da un insieme dinamico di nodi fisici o virtuali. Questi nodi formano uno strato di storage oggetti resiliente, tollerante ai guasti e basato su politiche che alimenta Cubbit DS3.
Al suo interno, un Swarm è responsabile per lo storage sicuro e ridondante di oggetti. Gli oggetti vengono divisi, crittografati e codificati in frammenti, che vengono poi distribuiti tra i nodi per garantire durabilità, conformità e prestazioni. La logica di posizionamento e ridondanza è disciplinata dalle Classi di Ridondanza, ed abilita la resilienza a più livelli sia a livello di nodo che geografico.
Gli Swarm possono essere distribuiti secondo una vasta gamma di topologie, da setup semplici su sito singolo a reti infrastrutturali complesse e multi-regione, consentendo alle organizzazioni di adattare le politiche di storage a vincoli operativi, requisiti normativi o a requisiti di performance.
Architettura
Per offrire questo livello di flessibilità e resilienza, un Swarm è composto da diversi elementi fondamentali:
- Nodi, che forniscono capacità di storage
- Agenti, che gestiscono dischi individuali
- Rings, che organizzano gli agenti secondo le politiche di ridondanza
- Classi di Ridondanza, che definiscono le regole di protezione e distribuzione dei dati
- Nexus, che raggruppano nodi per prossimità o per probabilità di downtime
Le sezioni seguenti spiegano ciascun componente e descrivono come essi interagiscono per offrire uno storage distribuito, altamente performante e tollerante ai guasti.
Nodi
I Nodi sono gli elementi infrastrutturali fondamentali in uno Swarm. Rappresentano macchine fisiche o virtuali che contribuiscono con capacità di storage grezzo al sistema. Un nodo può trovarsi in un data center, all'edge o in un ambiente cloud completamente virtualizzato.
Ogni nodo si collega al Coordinator, che monitora il suo stato, assegna ruoli e coordina la sua partecipazione nelle operazioni di storage. Gli operatori registrano manualmente i nodi, che possono essere aggiunti in modo incrementale per espandere il sistema senza interruzioni.
Agenti
Gli Agenti sono processi leggeri e containerizzati che eseguono su ciascun Nodo. Ogni Agente gestisce un singolo disco e si occupa di:
- Gestire frammenti di dati crittografati
- Eseguire operazioni di upload e download
- Segnalare lo stato di salute del disco e le informazioni di telemetria
- Applicare politiche di ridondanza a livello di disco
Un Nodo ospita tipicamente uno o più agenti (a seconda da quanti dischi controlla), consentendo un controllo preciso sull'allocazione dello storage e un recupero dei guasti avanzato. Poiché gli Agenti operano a livello di disco, consentono una gestione efficiente del ciclo di vita del disco e aiutano a minimizzare la perdita di dati in caso di problemi hardware.
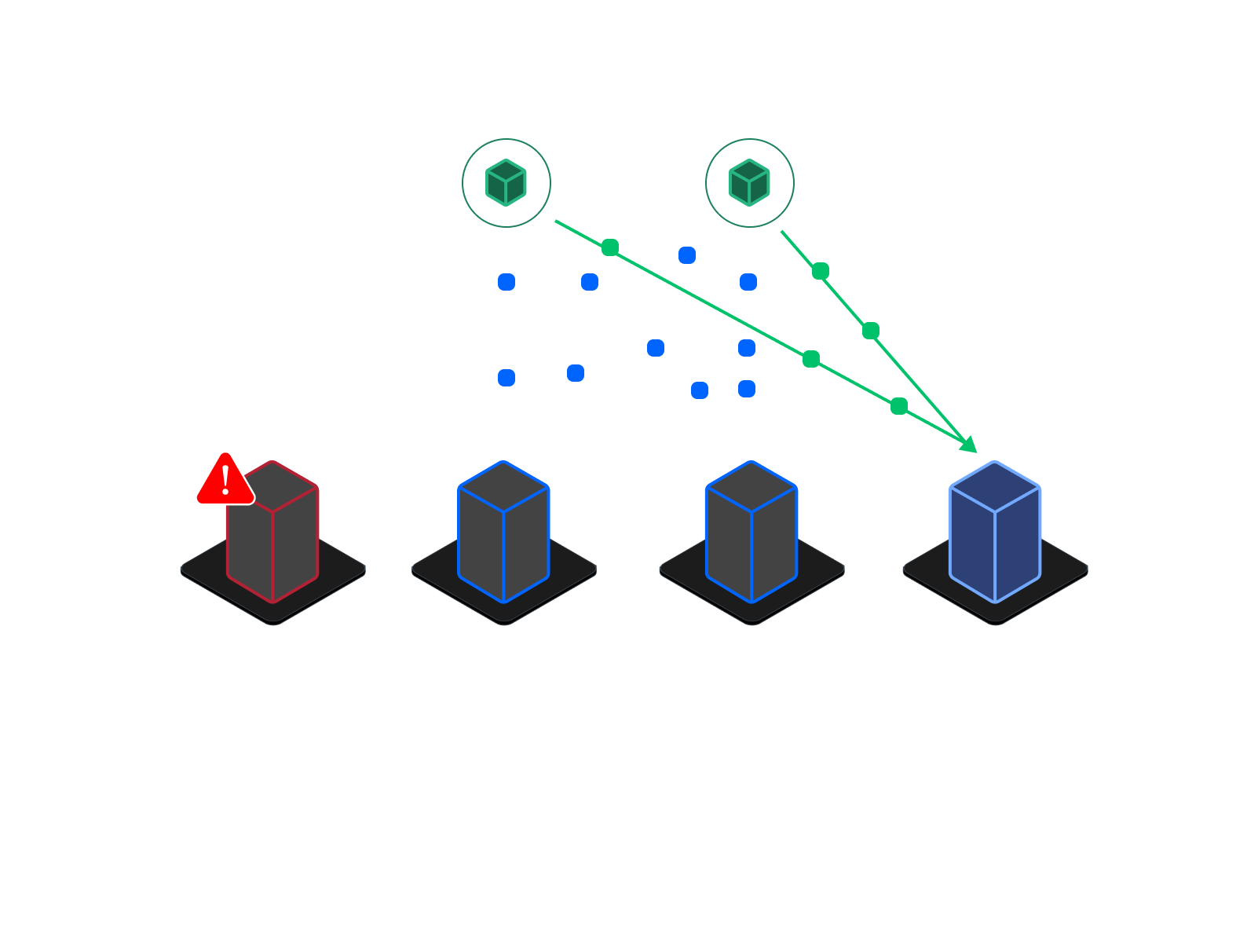
Nexus
Un Nexus è un raggruppamento logico di Nodi la cui probabilità di downtime è correlata — come un data center, una zona di disponibilità o una regione. I Nexuses sono le unità fondamentali per abilitare politiche di storage geo-distribuite e di ripristino da disastri.
Scopo dei Nexuses
- Isolamento del dominio di guasto: Diffondendo i frammenti su più Nexuses, il sistema minimizza il rischio che un incidente localizzato (ad es., un'interruzione di corrente del data center) possa compromettere la disponibilità dei dati.
- Residenza e conformità dei dati: I Nexuses possono essere isolati in regioni o paesi specifici per soddisfare i requisiti normativi (ad es., GDPR, ISO, leggi sulla sovranità nazionale).
- Prestazioni di recovery: I guasti locali (ad es., un nodo o un disco) sono tipicamente gestibili all'interno dello stesso Nexus, offrendo riparazioni più rapide e un minor utilizzo della larghezza di banda intersito.
Caratteristiche
Ogni Nexus contiene un numero flessibile di Nodi. I Nodi possono essere aggiunti a un Nexus dinamicamente nel tempo. I Nexuses sono referenziati dalle Classi di Ridondanza, che ne definiscono il numero necessario per memorizzare o ricostruire i dati. È possibile pensare a un Nexus come a una availability zone — un sito delimitato e affidabile utilizzato per distribuire storage e ottimizzare la disaster recovery.
Classi di Ridondanza
Una volta che i Nodi sono organizzati in Nexuses, le Classi di Ridondanza (RC) definiscono come i dati sono memorizzati su queste risorse — sia localmente che geograficamente. Una Classe di Ridondanza è una politica che configura:
| Parametro | Descrizione |
|---|---|
| Numero di Nexuses richiesti per ricostruire i dati | |
| Numero di Nexuses aggiuntivi per ridondanza | |
| Numero di Agenti per Nexus necessario per la ricostruzione locale | |
| Agenti aggiuntivi per Nexus per ridondanza a livello di nodo | |
| Numero massimo di Agenti per nodo (Anti-Affinity Group) |
Ogni RC porta a uno schema di codifica Reed-Solomon a due livelli:
- Ridondanza Locale: Protegge contro guasti di disco o nodo all'interno di un Nexus.
- Ridondanza Geografica: Protegge contro guasti a livello di sito tra Nexus.
- Vincoli AAG: Garantisce l'isolamento fisico dei frammenti di file su hardware separati.
L'overhead di capacità introdotto dalla classe di ridondanza vien definito ratio ed è uguale a
Esempio: Configurazione Resiliente Multi-sito
Configurazione
Questa configurazione richiede:
- 5 Nexus totali (3 necessari per il recupero dei dati + 2 per la ridondanza)
- 6 Agenti per Nexus (4 + 2), ciascuno su un host fisico separato
Con questa configurazione, il sistema può perdere:
- Fino a 2 Nexus interi
- Fino a 2 nodi per Nexus sopravvissuto ...senza alcuna perdita di dati.
Esempio: Configurazione ottimizzata per scenari Edge
Configurazione
Con questa configurazione:
- Tutti i dati rimangono localizzati in un Nexus.
- Può tollerare tre guasti di nodi all'interno dello stesso sito.
- Ideale per ambienti limitati e a basso costo.
Perché è importante
Le Classi di Ridondanza consentono agli Operatori di:
- Affinare i compromessi tra resilienza e costo
- Definire storage tiers per diversi Tenant o Progetti
- Conformarsi a geo-fencing, anti-affinità e obiettivi di performance
- Evolvere l'infrastruttura senza riprogettare il Swarm
Multiple RCs possono coesistere nello stesso Swarm — ciascuna supportata dai propri Ring, che tratteremo qui sotto.
Rings
Un Ring è un'istanza concreta di una Classe di Ridondanza — un gruppo di Agenti che memorizzano e gestiscono i dati secondo una specifica politica.
Ciascun Anello:
- Implementa una e una sola Classe di Ridondanza
- Contiene un insieme di Agenti distribuiti su uno o più Nexuses
- Funziona come un'unità indipendente di capacità di storage
Comportamento del Ring
- I Ring definiscono il set attivo di Agenti utilizzati per memorizzare nuovi dati.
- Quando un Ring si avvicina alla massima capacità, può essere creato un nuovo Ring per la stessa Classe di Ridondanza.
- Gli Agenti possono partecipare in più Ring, abilitando multi-tenant, tiering caldi/freddi, o zone di storage isolate.
I Ring rendono lo Swarm modulare e scalabile: è possibile far crescere lo storage in modo incrementale, ottimizzare il posizionamento e riequilibrare i carichi di lavoro nel tempo senza riconfigurare l'intero sistema.
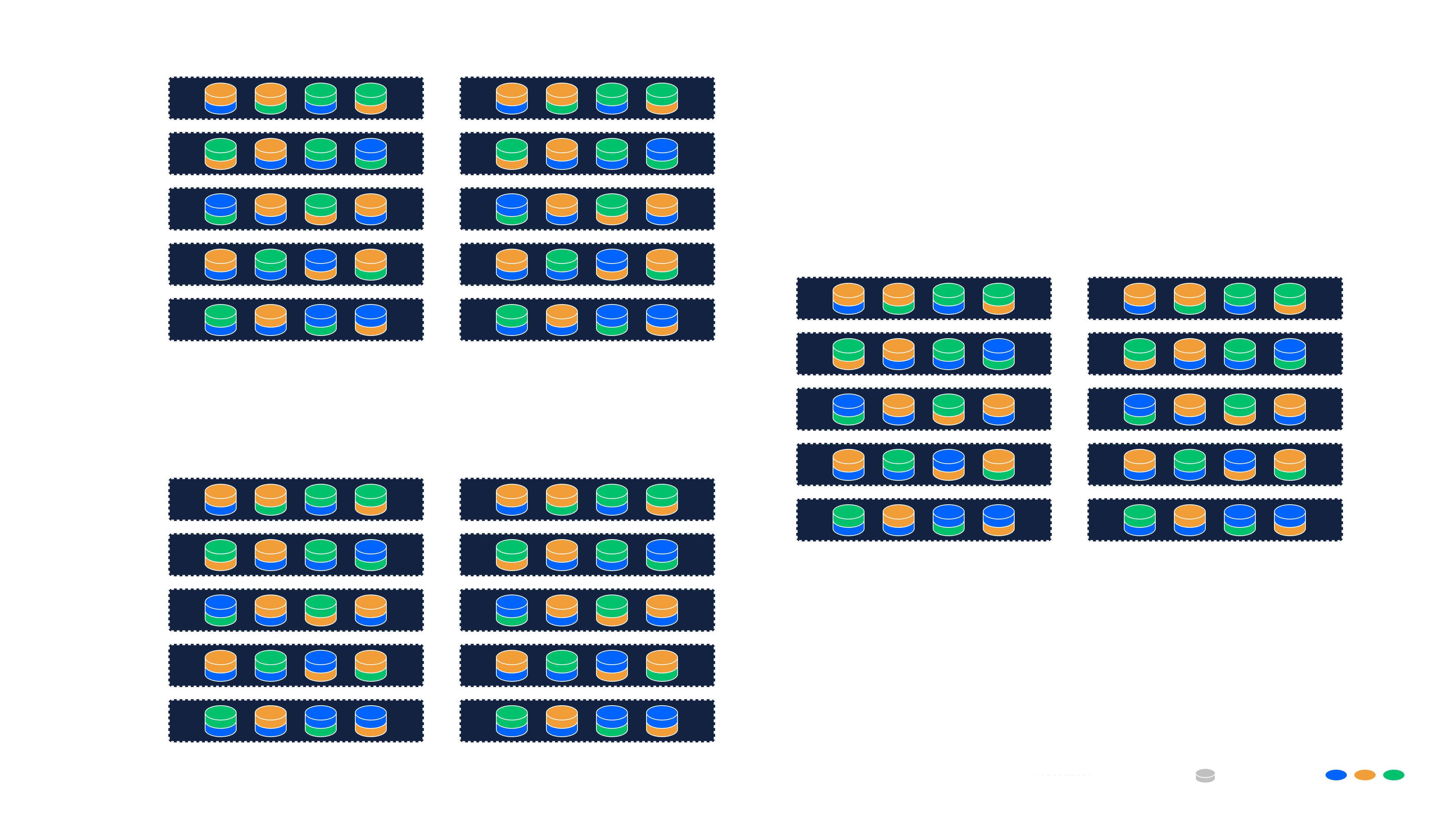
Esempio: Implementazione Single-Site con Ridondanza Locale
Questo esempio descrive una tipica implementazione single-site utilizzando 10 server, ciascuno con otto dischi (per un totale di 80 dischi). Tutti i server eseguono Agenti di storage, uno per disco.
Configurazione della Classe di Ridondanza
- (implementazione di Nexus singolo)
- (20 frammenti per oggetto)
- (non più di due frammenti da un Ring sullo stesso server fisico)
Questa Classe di Ridondanza porta ai seguenti risultati:
- Un Fattore di Ridondanza di 1,25×: Ogni oggetto è suddiviso in 16 frammenti di dati e 4 frammenti di parità ( frammenti). Poiché sono necessari solo 16 frammenti per il recupero, il sistema raggiunge un'overhead di storage del 25% per ridondanza (= ).
- Rings: Il sistema può istanziare automaticamente o manualmente 4 Ring indipendenti. Questi Ring possono essere visualizzati come quattro set colorati di 20 Agenti ciascuno nell'immagine sottostante, distribuendo il carico e isolando le unità di capacità.

Comportamento
- Ciascuno dei 20 frammenti è memorizzato su un disco diverso (Agente) all'interno di un Ring.
- Qualsiasi 16 frammenti sono sufficienti per ricostruire l'oggetto originale.
- Il vincolo aag = 2 garantisce che non più di due frammenti di un Ring siano memorizzati sullo stesso server fisico.
- Questo significa che il sistema può tollerare il guasto di un massimo di 2 interi server all'interno di un Ring senza alcuna perdita di dati.
Questa configurazione offre un'architettura robusta ed efficiente per implementazioni aziendali on-premise, con tolleranza ai guasti prevedibile e ottimizzazione dell'utilizzo delle risorse.
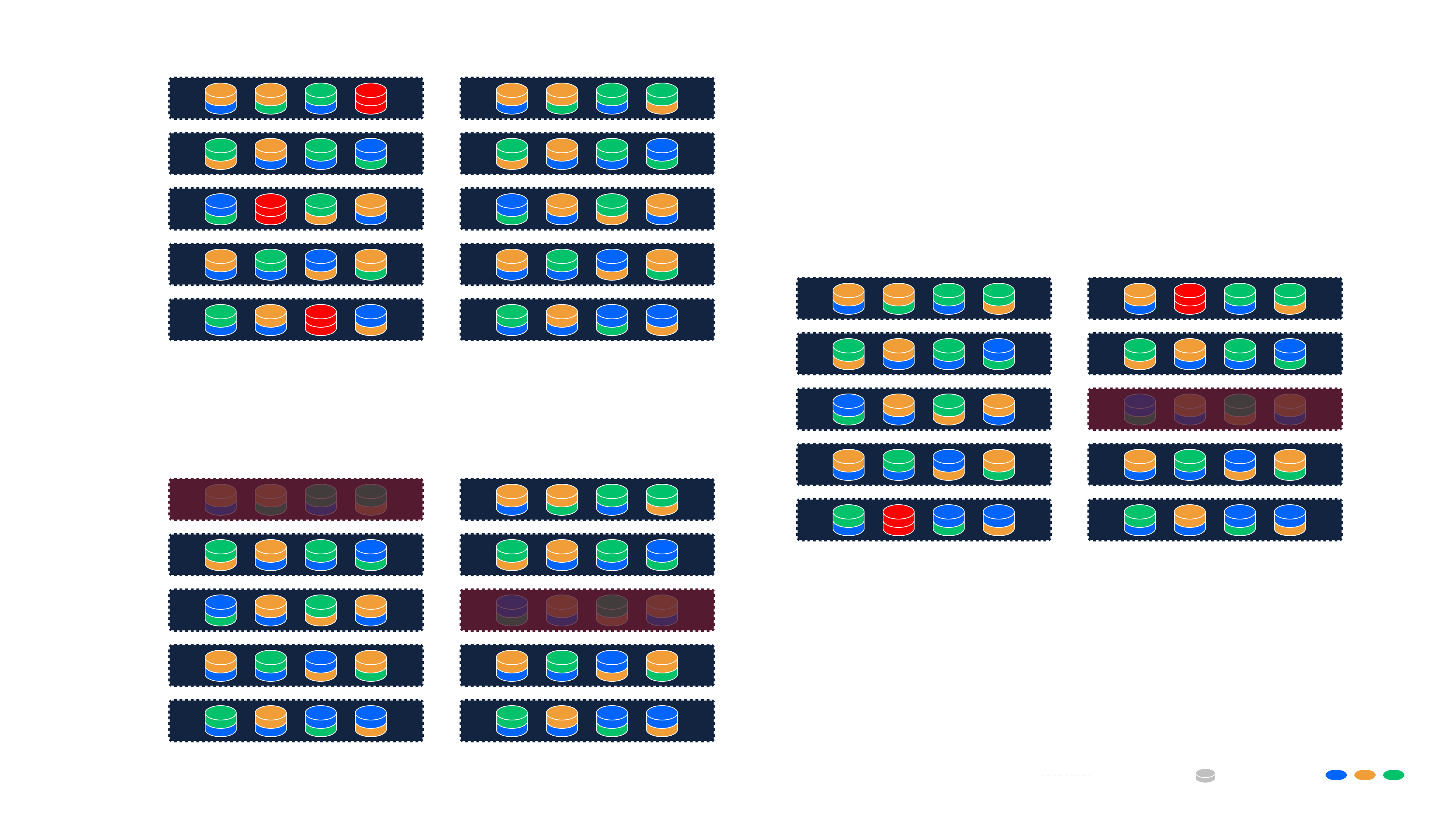
Esempio: implementazione multi-sito con geo-ridondanza
In questo esempio, estendiamo il setup single-site a un'implementazione multi-sito geo-ridondante attraverso tre siti indipendenti. L'infrastruttura segue la stessa configurazione locale (16 + 4 frammenti per oggetto, AAG = 2) ma introduce tolleranza ai guasti a livello geografico.
Configurazione della Classe di Ridondanza
- (i dati possono essere recuperati da qualsiasi 2 dei 3 siti)
- (come esempio sopra)
Comportamento
- I dati sono distribuiti su 3 Nexus (uno per sito).
- Ogni sito memorizza 20 frammenti (16 + 4) per oggetto, seguendo la politica di ridondanza locale.
- Solo due dei tre siti sono necessari per ripristinare completamente qualsiasi oggetto—il terzo funge da riserva.
- Questo protegge contro i guasti a livello di sito mantenendo un rapido recupero locale da guasti di nodo o disco.
Tolleranza ai guasti
Questa configurazione può tollerare:
- Fino a 1 guasto dell'intero sito
- Fino a 2 guasti di server per sito
- Fino a 4 guasti di disco per sito
Fattore di Ridondanza
- Il fattore di ridondanza locale rimane 1,25× (20 frammenti / 16 richiesti).
- Il fattore di ridondanza geografico aggiunge un ulteriore 1,5× di overhead (3 siti dei quali 2 richiesti).
- Il fattore di ridondanza combinato risultante è 1,875×:
Capacità Raw Totale / Capacità Utilizzabile =
In altre parole, per ogni 1,875 TB di storage raw, puoi aspettarti 1 TB di capacità utilizzabile.
Questa configurazione trova un eccellente equilibrio tra alta durabilità e utilizzo efficiente delle risorse. Mescolando Nexus e Ring, gli operatori possono ottenere un'eccezionale tolleranza ai guasti con un aumento relativamente modesto della ridondanza.
Auto-ripristino e recovery
Gli Swarm DS3 sono progettati per auto-ripararsi e recuperare automaticamente da guasti hardware localizzati e interruzioni su larga scala del sito. A seconda dell'ambito del guasto, le operazioni di recupero avvengono a due livelli: locale (intra-Nexus) e geografico (cross-Nexus).
Rilevamento dei Guasti
Il Coordinator monitora continuamente la salute di tutti i nodi, Agenti e Nexus in tempo reale. Se una soglia viene superata—come un disco che diventa non responsivo o un Nexus che va offline—vengono generati avvisi e i flussi di lavoro di recupero possono essere avviati automaticamente o tramite l'API/l'azione dell'utente.
Recupero Locale (Intra-Nexus)
Quando un nodo o disco fallisce all'interno di un Nexus:
- I componenti guasti vengono sostituiti, e nuovi Agenti vengono distribuiti.
- Gli operatori possono avviare il recupero tramite l'interfaccia web o API DS3.
- Gli Agenti nel Ring interessato stabiliscono connessioni peer-to-peer (P2P) con Agenti sani nello stesso Nexus.
- I frammenti mancanti vengono ricostruiti utilizzando la parità Reed-Solomon e ridistribuiti per ripristinare il livello di ridondanza originale.
Questo processo ripristina l'integrità del sistema senza necessità di accedere a Nexus esterni, minimizzando l'uso della larghezza di banda e ottimizzando la velocità di recupero.
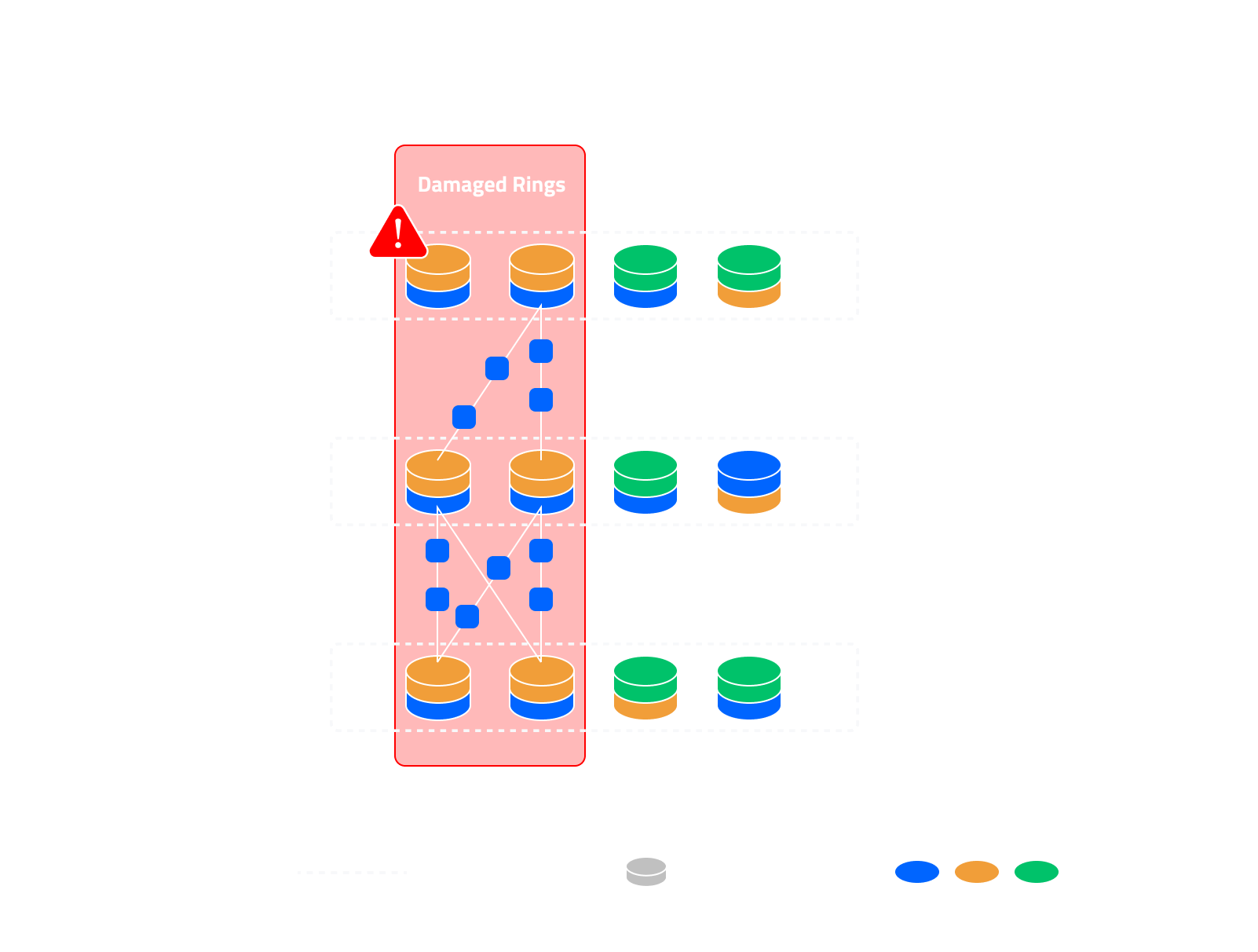
Recupero Geografico (Cross-Nexus)
Quando un intero Nexus diventa non disponibile:
- Un nuovo Nexus viene creato provvedendo e registrando nodi di sostituivi.
- I Gateway DS3 assistono nel recupero scaricando un numero sufficiente di frammenti di dati dai Nexus rimanenti per ricostruire i segmenti mancanti.
- Gli strati di ridondanza sono invertiti e ricodificati per generare i frammenti richiesti.
- Questi vengono poi distribuiti al nuovo Nexus, ripristinando la ridondanza e la capacità.
Questo assicura che anche le interruzioni regionali su larga scala non compromettano la durata o la disponibilità dei dati.